 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative and Discriminative Deep Belief Network Classifiers: Comparisons Under an Approximate Computing Framework
Paper and Code
Jan 31, 2021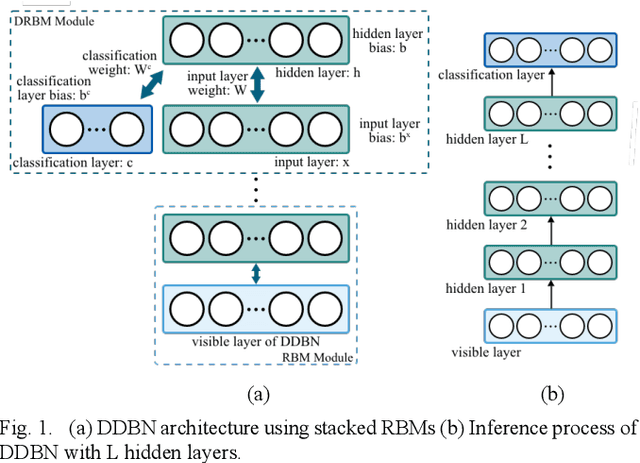
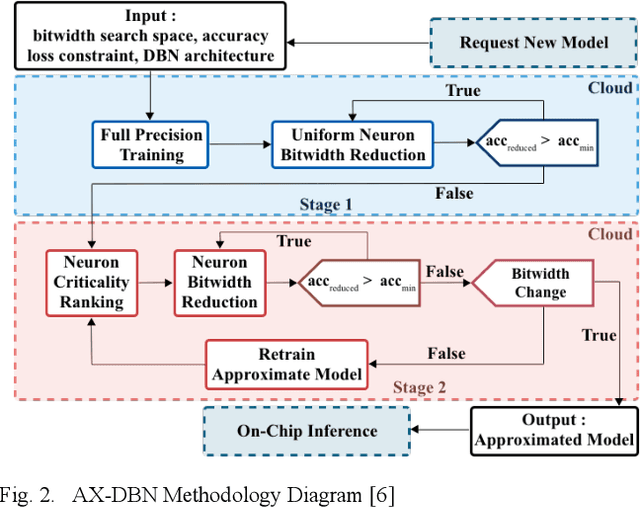

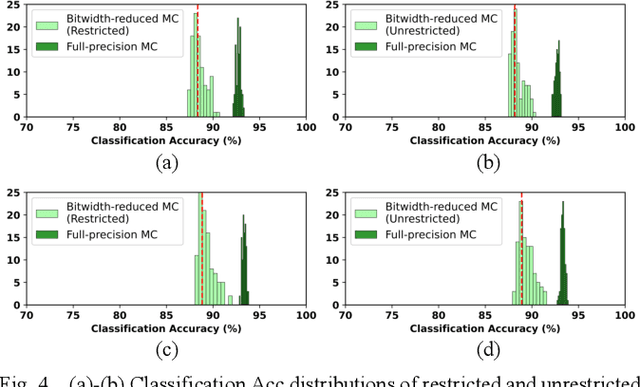
The use of Deep Learning hardware algorithms for embedded applications is characterized by challenges such as constraints on device power consumption, availability of labeled data, and limited internet bandwidth for frequent training on cloud servers. To enable low power implementations, we consider efficient bitwidth reduction and pruning for the class of Deep Learning algorithms known as Discriminative Deep Belief Networks (DDBNs) for embedded-device classification tasks. We train DDBNs with both generative and discriminative objectives under an approximate computing framework and analyze their power-at-performance for supervised and semi-supervised applications. We also investigate the out-of-distribution performance of DDBNs when the inference data has the same class structure yet is statistically different from the training data owing to dynamic real-time operating environments. Based on our analysis, we provide novel insights and recommendations for choice of training objectives, bitwidth values, and accuracy sensitivity with respect to the amount of labeled data for implementing DDBN inference with minimum power consumption on embedded hardware platforms subject to accuracy tolerances.