 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Networks Unlearning
Paper and Code
Aug 19, 2023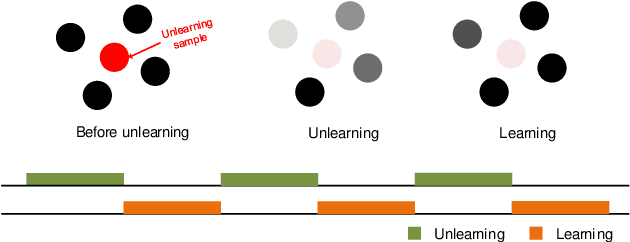

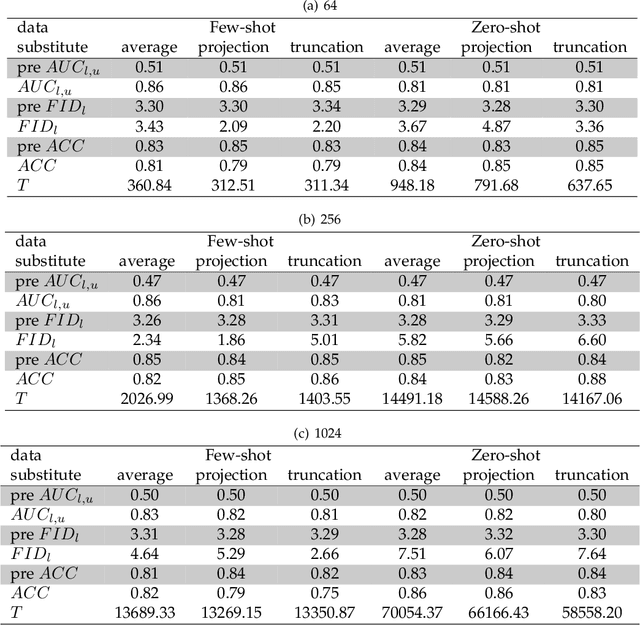
As machine learning continues to develop, and data misuse scandals become more prevalent, individuals are becoming increasingly concerned about their personal information and are advocating for the right to remove their data. Machine unlearning has emerged as a solution to erase training data from trained machine learning models. Despite its success in classifiers, research on Generative Adversarial Networks (GANs) is limited due to their unique architecture, including a generator and a discriminator. One challenge pertains to generator unlearning, as the process could potentially disrupt the continuity and completeness of the latent space. This disruption might consequently diminish the model's effectiveness after unlearning. Another challenge is how to define a criterion that the discriminator should perform for the unlearning images. In this paper, we introduce a substitution mechanism and define a fake label to effectively mitigate these challenges. Based on the substitution mechanism and fake label, we propose a cascaded unlearning approach for both item and class unlearning within GAN models, in which the unlearning and learning processes run in a cascaded manner. We conducted a comprehensive evaluation of the cascaded unlearning technique using the MNIST and CIFAR-10 datasets. Experimental results demonstrate that this approach achieves significantly improved item and class unlearning efficiency, reducing the required time by up to 185x and 284x for the MNIST and CIFAR-10 datasets, respectively, in comparison to retraining from scratch. Notably, although the model's performance experiences minor degradation after unlearning, this reduction is negligible when dealing with a minimal number of images (e.g., 64) and has no adverse effects on downstream tasks such as classification.