 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Network for Future Hand Segmentation from Egocentric Video
Paper and Code
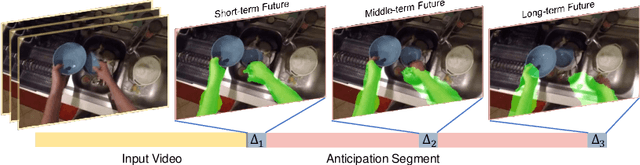
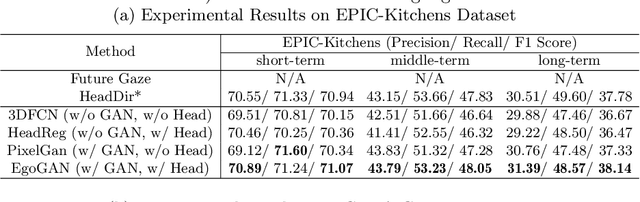
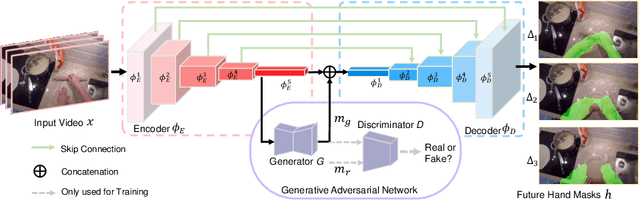
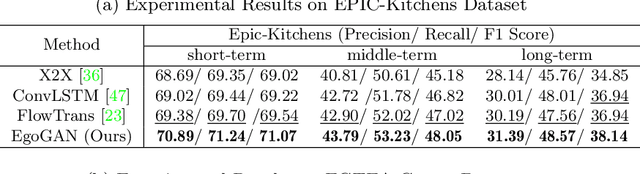
We introduce the novel problem of anticipating a time series of future hand masks from egocentric video. A key challenge is to model the stochasticity of future head motions, which globally impact the head-worn camera video analysis. To this end, we propose a novel deep generative model -- EgoGAN, which uses a 3D Fully Convolutional Network to learn a spatio-temporal video representation for pixel-wise visual anticipation, generates future head motion using Generative Adversarial Network (GAN), and then predicts the future hand masks based on the video representation and the generated future head motion. We evaluate our method on both the EPIC-Kitchens and the EGTEA Gaze+ datasets. We conduct detailed ablation studies to validate the design choices of our approach. Furthermore, we compare our method with previous state-of-the-art methods on future image segmentation and show that our method can more accurately predict future hand masks.