 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Privacy-Preserving Process Data with Deep Generative Models
Paper and Code
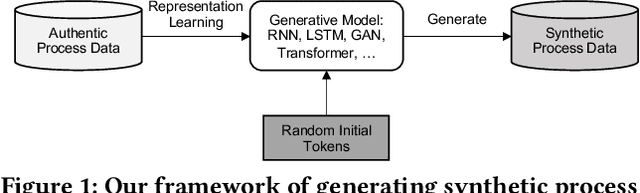
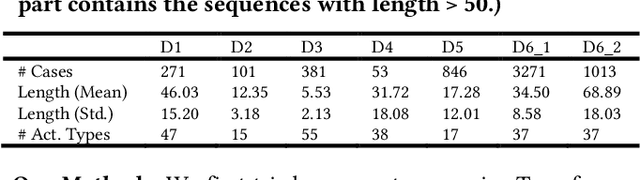
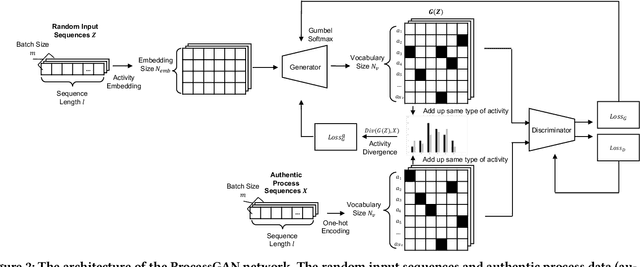
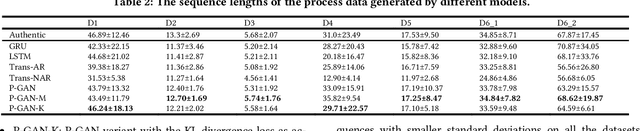
Process data with confidential information cannot be shared directly in public, which hinders the research in process data mining and analytics. Data encryption methods have been studied to protect the data, but they still may be decrypted, which leads to individual identification. We experimented with different models of representation learning and used the learned model to generate synthetic process data. We introduced an adversarial generative network for process data generation (ProcessGAN) with two Transformer networks for the generator and the discriminator. We evaluated ProcessGAN and traditional models on six real-world datasets, of which two are public and four are collected in medical domains. We used statistical metrics and supervised learning scores to evaluate the synthetic data. We also used process mining to discover workflows for the authentic and synthetic datasets and had medical experts evaluate the clinical applicability of the synthetic workflows. We found that ProcessGAN outperformed traditional sequential models when trained on small authentic datasets of complex processes. ProcessGAN better represented the long-range dependencies between the activities, which is important for complicated processes such as the medical processes. Traditional sequential models performed better when trained on large data of simple processes. We conclude that ProcessGAN can generate a large amount of sharable synthetic process data indistinguishable from authentic data.