 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Mathematical Derivations with Large Language Models
Paper and Code
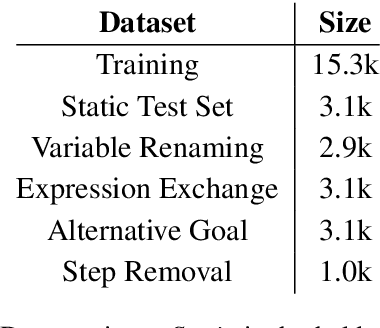

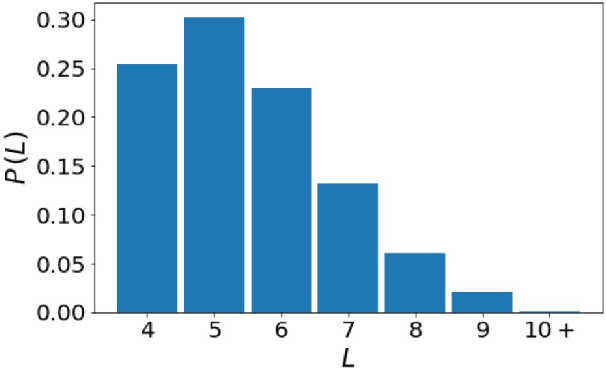

The derivation of mathematical results in specialised fields, using Large Language Models (LLMs), is an emerging research direction that can help identify models' limitations, and potentially support mathematical discovery. In this paper, we leverage a symbolic engine to generate derivations of equations at scale, and investigate the capabilities of LLMs when deriving goal equations from premises. Specifically, we employ in-context learning for GPT and fine-tune a range of T5 models to compare the robustness and generalisation of pre-training strategies to specialised models. Empirical results show that fine-tuned FLAN-T5-large (MathT5) outperforms GPT models on all static and out-of-distribution test sets in conventional scores. However, an in-depth analysis reveals that the fine-tuned models are more sensitive to perturbations involving unseen symbols and (to a lesser extent) changes to equation structure. In addition, we analyse 1.7K equations, and over 200 derivations, to highlight common reasoning errors such as the inclusion of incorrect, irrelevant, and redundant equations. Finally, we explore the suitability of existing metrics for evaluating mathematical derivations and find evidence that, while they can capture general properties such as sensitivity to perturbations, they fail to highlight fine-grained reasoning errors and essential differences between models. Overall, this work demonstrates that training models on synthetic data may improve their math capabilities beyond much larger LLMs, but current metrics are not appropriately assessing the quality of generated mathematical text.