 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Fast and Slow: Scene Decomposition via Reconstruction
Paper and Code
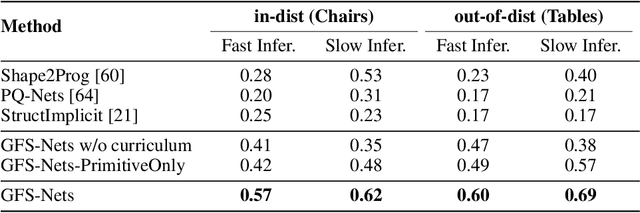
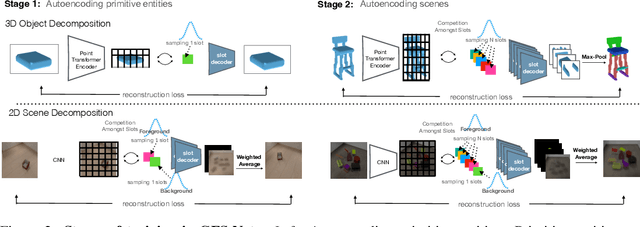
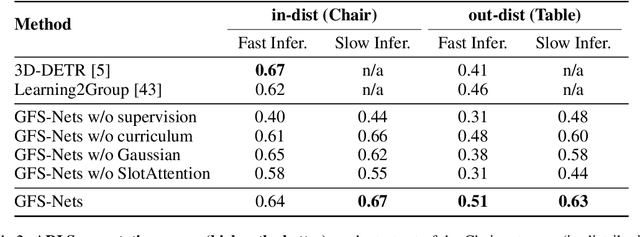
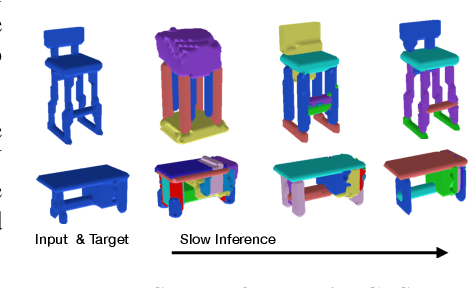
We consider the problem of segmenting scenes into constituent entities, i.e. underlying objects and their parts. Current supervised visual detectors though impressive within their training distribution, often fail to segment out-of-distribution scenes into their constituent entities. Recent slot-centric generative models break such dependence on supervision, by attempting to segment scenes into entities unsupervised, by reconstructing pixels. However, they have been restricted thus far to toy scenes as they suffer from a reconstruction-segmentation trade-off: as the entity bottleneck gets wider, reconstruction improves but then the segmentation collapses. We propose GFS-Nets (Generating Fast and Slow Networks) that alleviate this issue with two ingredients: i) curriculum training in the form of primitives, often missing from current generative models and, ii) test-time adaptation per scene through gradient descent on the reconstruction objective, what we call slow inference, missing from current feed-forward detectors. We show the proposed curriculum suffices to break the reconstruction-segmentation trade-off, and slow inference greatly improves segmentation in out-of-distribution scenes. We evaluate GFS-Nets in 3D and 2D scene segmentation benchmarks of PartNet, CLEVR, Room Diverse++, and show large ( 50%) performance improvements against SOTA supervised feed-forward detectors and unsupervised object discovery methods