 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Attention from Classifier Activations for Fine-grained Recognition
Paper and Code
Nov 27, 2018

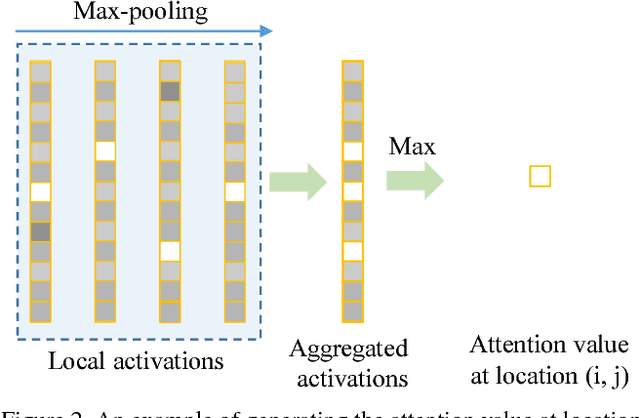
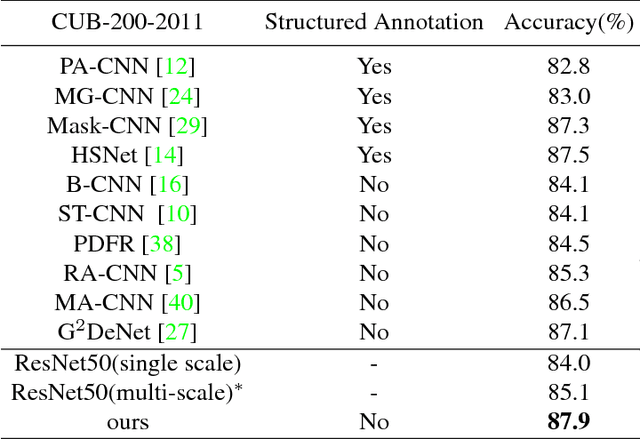
Recent advances in fine-grained recognition utilize attention maps to localize objects of interest. Although there are many ways to generate attention maps, most of them rely on sophisticated loss functions or complex training processes. In this work, we propose a simple and straightforward attention generation model based on the output activations of classifiers. The advantage of our model is that it can be easily trained with image level labels and softmax loss functions. More specifically, multiple linear local classifiers are firstly adopted to perform fine-grained classification at each location of high level CNN feature maps. The attention map is generated by aggregating and max-pooling the output activations. Then the attention map serves as a surrogate target object mask to train those local classifiers, similar to training models for semantic segmentation. Our model achieves state-of-the-art results on three heavily benchmarked datasets, i.e. 87.9% on CUB-200-2011 dataset, 94.1% on Stanford Cars dataset and 92.1% on FGVC-Aircraft dataset, demonstrating its effectiveness on fine-grained recognition tasks.