 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing through Forgetting -- Domain Generalization for Symptom Event Extraction in Clinical Notes
Paper and Code
Sep 20, 2022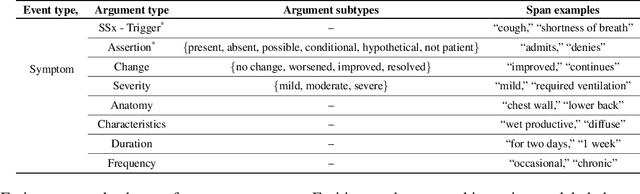
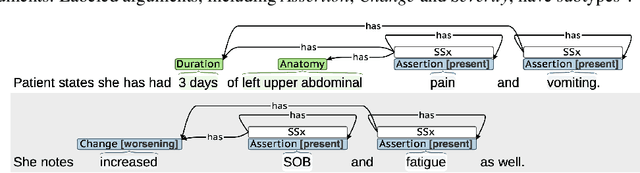

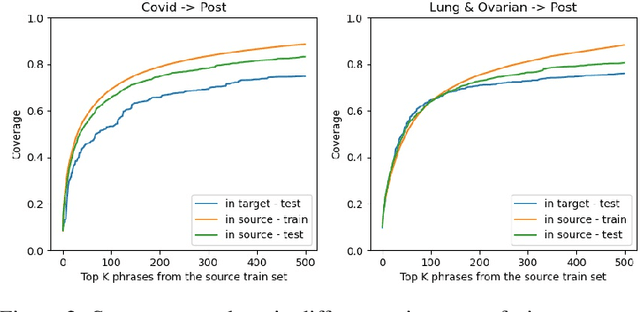
Symptom information is primarily documented in free-text clinical notes and is not directly accessible for downstream applications. To address this challenge, information extraction approaches that can handle clinical language variation across different institutions and specialties are needed. In this paper, we present domain generalization for symptom extraction using pretraining and fine-tuning data that differs from the target domain in terms of institution and/or specialty and patient population. We extract symptom events using a transformer-based joint entity and relation extraction method. To reduce reliance on domain-specific features, we propose a domain generalization method that dynamically masks frequent symptoms words in the source domain. Additionally, we pretrain the transformer language model (LM) on task-related unlabeled texts for better representation. Our experiments indicate that masking and adaptive pretraining methods can significantly improve performance when the source domain is more distant from the target domain.