 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Emphatic Temporal Difference Learning: Bias-Variance Analysis
Paper and Code
Nov 27, 2015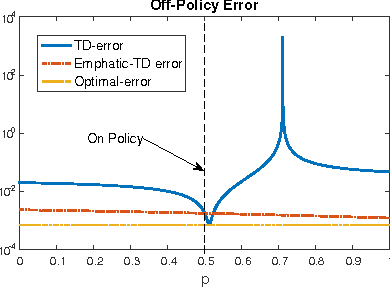
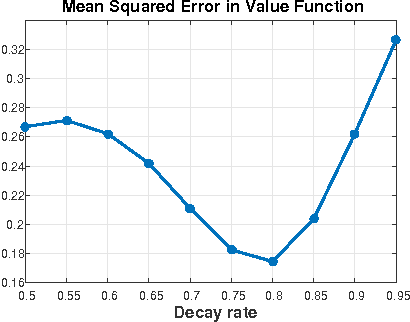
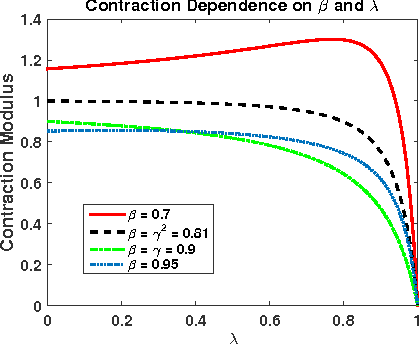
We consider the off-policy evaluation problem in Markov decision processes with function approximation. We propose a generalization of the recently introduced \emph{emphatic temporal differences} (ETD) algorithm \citep{SuttonMW15}, which encompasses the original ETD($\lambda$), as well as several other off-policy evaluation algorithms as special cases. We call this framework \ETD, where our introduced parameter $\beta$ controls the decay rate of an importance-sampling term. We study conditions under which the projected fixed-point equation underlying \ETD\ involves a contraction operator, allowing us to present the first asymptotic error bounds (bias) for \ETD. Our results show that the original ETD algorithm always involves a contraction operator, and its bias is bounded. Moreover, by controlling $\beta$, our proposed generalization allows trading-off bias for variance reduction, thereby achieving a lower total error.