 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Boosting Algorithms for Convex Optimization
Paper and Code
Feb 14, 2012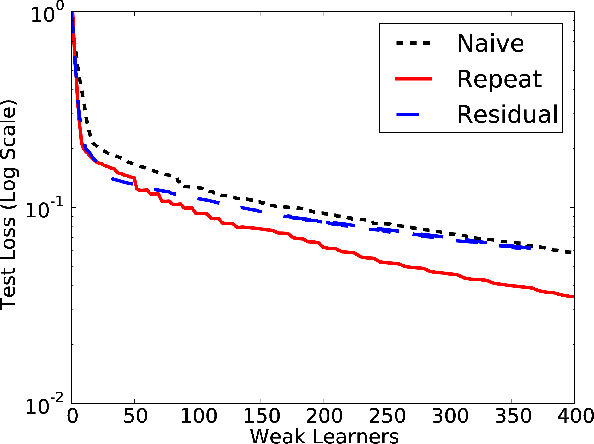
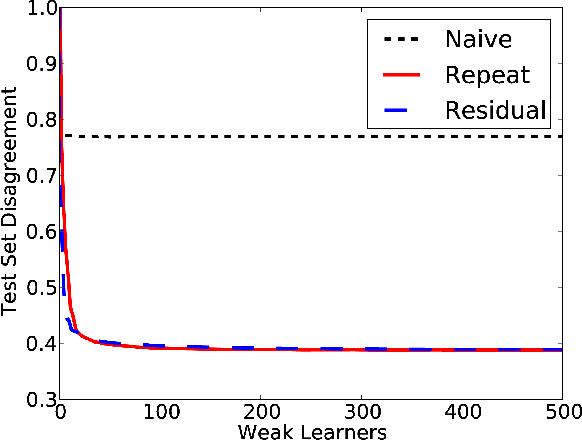

Boosting is a popular way to derive powerful learners from simpler hypothesis classes. Following previous work (Mason et al., 1999; Friedman, 2000) on general boosting frameworks, we analyze gradient-based descent algorithms for boosting with respect to any convex objective and introduce a new measure of weak learner performance into this setting which generalizes existing work. We present the weak to strong learning guarantees for the existing gradient boosting work for strongly-smooth, strongly-convex objectives under this new measure of performance, and also demonstrate that this work fails for non-smooth objectives. To address this issue, we present new algorithms which extend this boosting approach to arbitrary convex loss functions and give corresponding weak to strong convergence results. In addition, we demonstrate experimental results that support our analysis and demonstrate the need for the new algorithms we present.