 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Supervised Learning Through Riemannian Contraction
Paper and Code
Jan 26, 2022

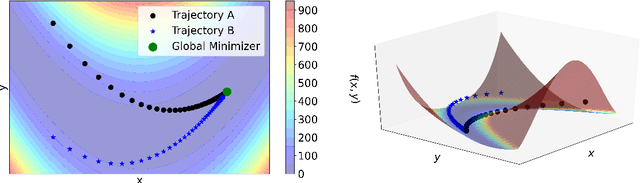

We prove that Riemannian contraction in a supervised learning setting implies generalization. Specifically, we show that if an optimizer is contracting in some Riemannian metric with rate $\lambda > 0$, it is uniformly algorithmically stable with rate $\mathcal{O}(1/\lambda n)$, where $n$ is the number of labelled examples in the training set. The results hold for stochastic and deterministic optimization, in both continuous and discrete-time, for convex and non-convex loss surfaces. The associated generalization bounds reduce to well-known results in the particular case of gradient descent over convex or strongly convex loss surfaces. They can be shown to be optimal in certain linear settings, such as kernel ridge regression under gradient flow.