 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization bounds for deep learning
Paper and Code

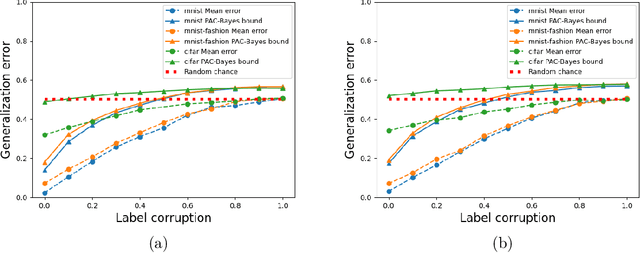
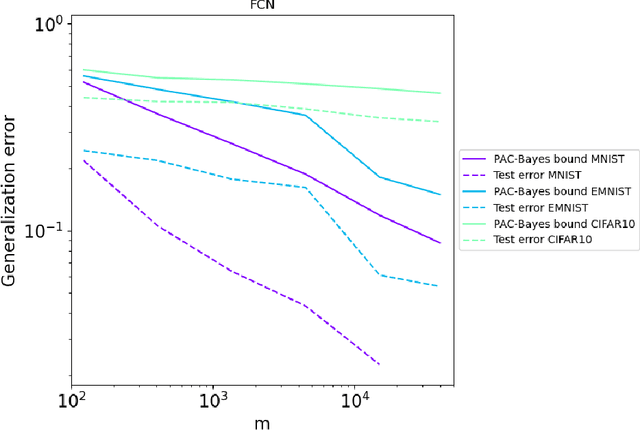
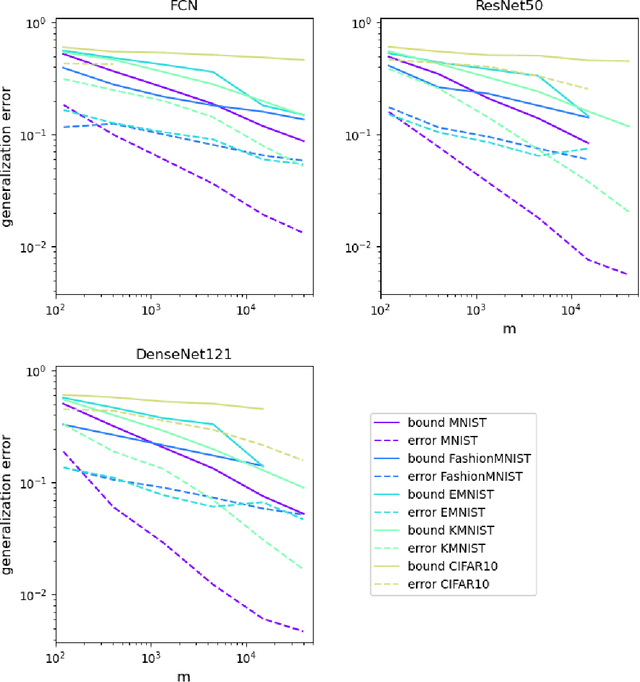
Generalization in deep learning has been the topic of much recent theoretical and empirical research. Here we introduce desiderata for techniques that predict generalization errors for deep learning models in supervised learning. Such predictions should 1) scale correctly with data complexity; 2) scale correctly with training set size; 3) capture differences between architectures; 4) capture differences between optimization algorithms; 5) be quantitatively not too far from the true error (in particular, be non-vacuous); 6) be efficiently computable; and 7) be rigorous. We focus on generalization error upper bounds, and introduce a categorisation of bounds depending on assumptions on the algorithm and data. We review a wide range of existing approaches, from classical VC dimension to recent PAC-Bayesian bounds, commenting on how well they perform against the desiderata. We next use a function-based picture to derive a marginal-likelihood PAC-Bayesian bound. This bound is, by one definition, optimal up to a multiplicative constant in the asymptotic limit of large training sets, as long as the learning curve follows a power law, which is typically found in practice for deep learning problems. Extensive empirical analysis demonstrates that our marginal-likelihood PAC-Bayes bound fulfills desiderata 1-3 and 5. The results for 6 and 7 are promising, but not yet fully conclusive, while only desideratum 4 is currently beyond the scope of our bound. Finally, we comment on why this function-based bound performs significantly better than current parameter-based PAC-Bayes bounds.