 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCS-M3VLT: Guided Context Self-Attention based Multi-modal Medical Vision Language Transformer for Retinal Image Captioning
Paper and Code
Dec 23, 2024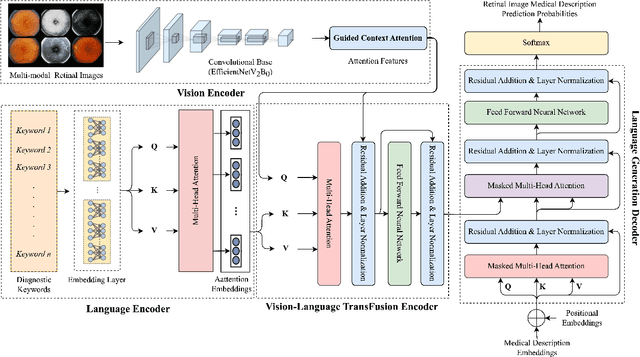
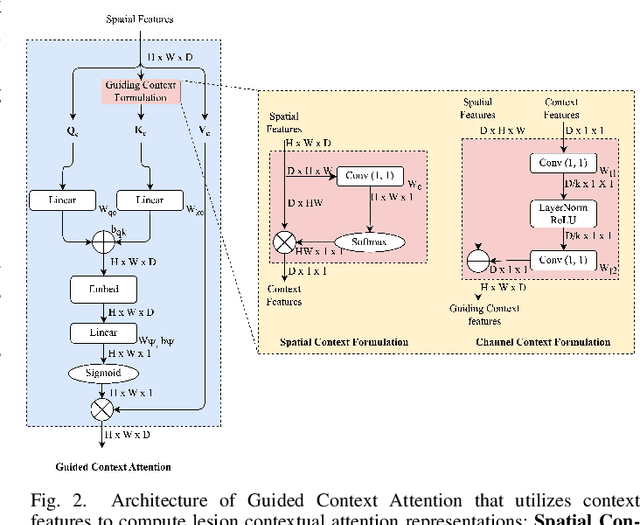
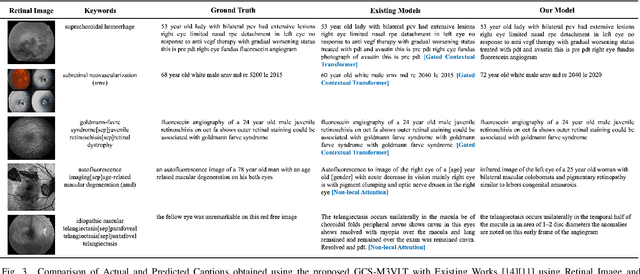
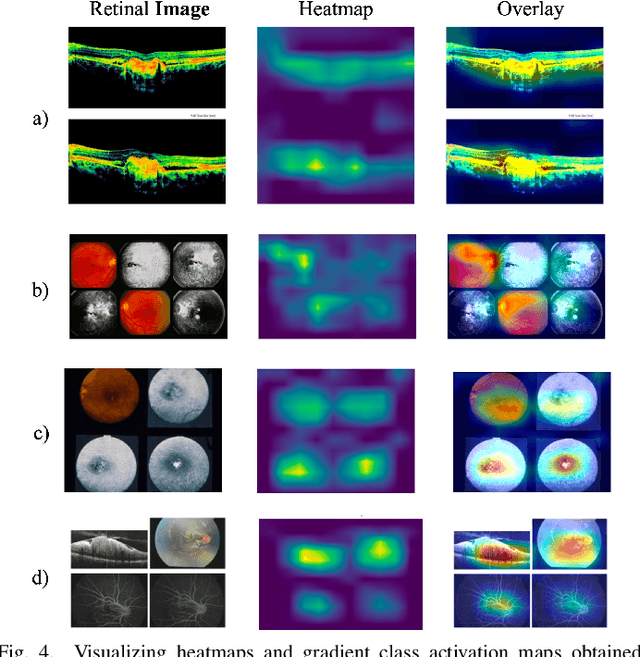
Retinal image analysis is crucial for diagnosing and treating eye diseases, yet generating accurate medical reports from images remains challenging due to variability in image quality and pathology, especially with limited labeled data. Previous Transformer-based models struggled to integrate visual and textual information under limited supervision. In response, we propose a novel vision-language model for retinal image captioning that combines visual and textual features through a guided context self-attention mechanism. This approach captures both intricate details and the global clinical context, even in data-scarce scenarios. Extensive experiments on the DeepEyeNet dataset demonstrate a 0.023 BLEU@4 improvement, along with significant qualitative advancements, highlighting the effectiveness of our model in generating comprehensive medical captions.