Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze Perception in Humans and CNN-Based Model
Paper and Code
Apr 17, 2021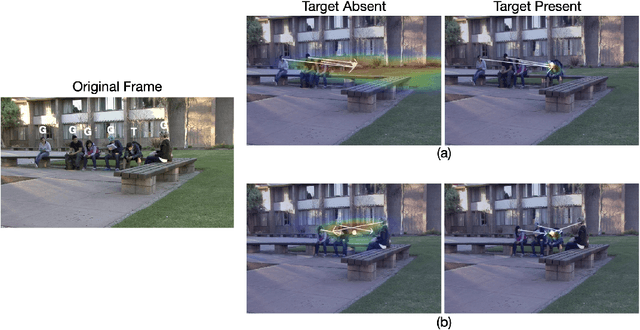
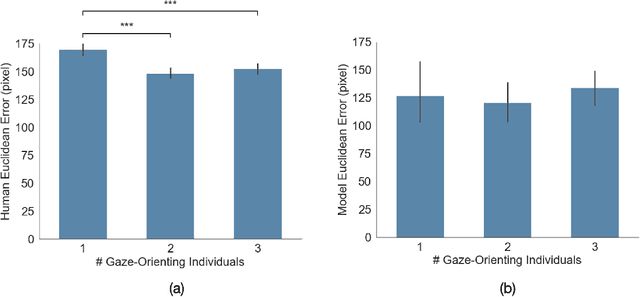
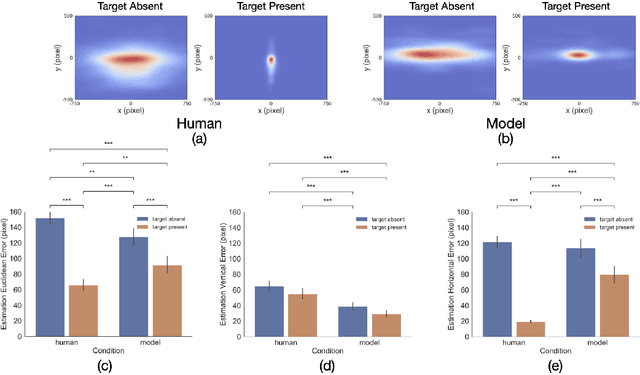
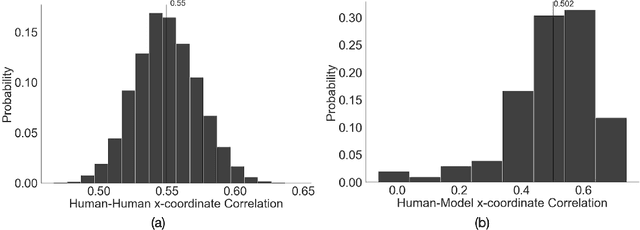
Making accurate inferences about other individuals' locus of attention is essential for human social interactions and will be important for AI to effectively interact with humans. In this study, we compare how a CNN (convolutional neural network) based model of gaze and humans infer the locus of attention in images of real-world scenes with a number of individuals looking at a common location. We show that compared to the model, humans' estimates of the locus of attention are more influenced by the context of the scene, such as the presence of the attended target and the number of individuals in the image.
View paper on