 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian mixture models with Wasserstein distance
Paper and Code
Jun 12, 2018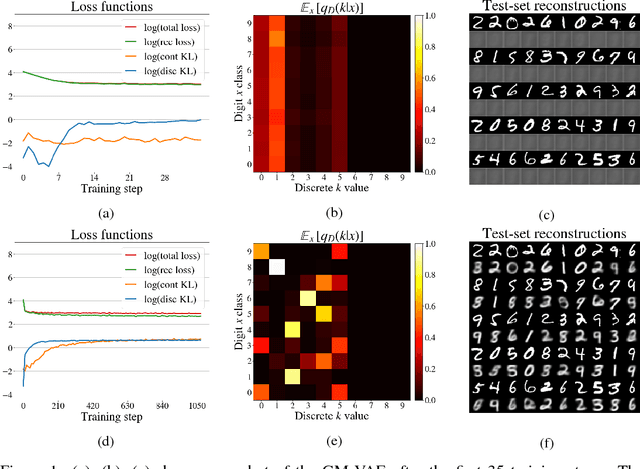



Generative models with both discrete and continuous latent variables are highly motivated by the structure of many real-world data sets. They present, however, subtleties in training often manifesting in the discrete latent being under leveraged. In this paper, we show that such models are more amenable to training when using the Optimal Transport framework of Wasserstein Autoencoders. We find our discrete latent variable to be fully leveraged by the model when trained, without any modifications to the objective function or significant fine tuning. Our model generates comparable samples to other approaches while using relatively simple neural networks, since the discrete latent variable carries much of the descriptive burden. Furthermore, the discrete latent provides significant control over generation.