 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGambler's Ruin Bandit Problem
Paper and Code
Sep 29, 2016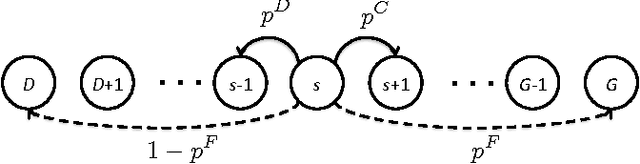
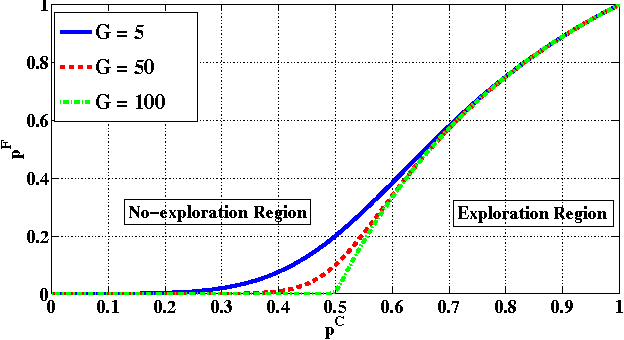
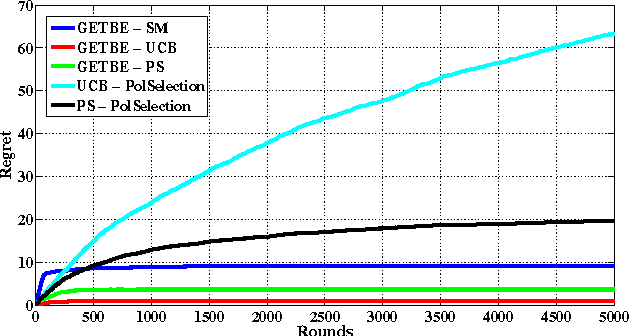
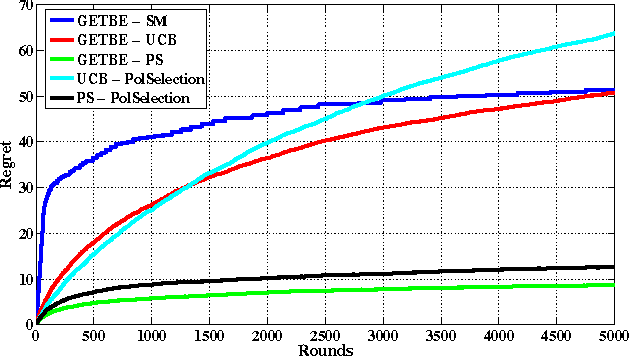
In this paper, we propose a new multi-armed bandit problem called the Gambler's Ruin Bandit Problem (GRBP). In the GRBP, the learner proceeds in a sequence of rounds, where each round is a Markov Decision Process (MDP) with two actions (arms): a continuation action that moves the learner randomly over the state space around the current state; and a terminal action that moves the learner directly into one of the two terminal states (goal and dead-end state). The current round ends when a terminal state is reached, and the learner incurs a positive reward only when the goal state is reached. The objective of the learner is to maximize its long-term reward (expected number of times the goal state is reached), without having any prior knowledge on the state transition probabilities. We first prove a result on the form of the optimal policy for the GRBP. Then, we define the regret of the learner with respect to an omnipotent oracle, which acts optimally in each round, and prove that it increases logarithmically over rounds. We also identify a condition under which the learner's regret is bounded. A potential application of the GRBP is optimal medical treatment assignment, in which the continuation action corresponds to a conservative treatment and the terminal action corresponds to a risky treatment such as surgery.