 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-DARTS-A: Groups of Channel Parallel Sampling with Attention
Paper and Code
Oct 16, 2020

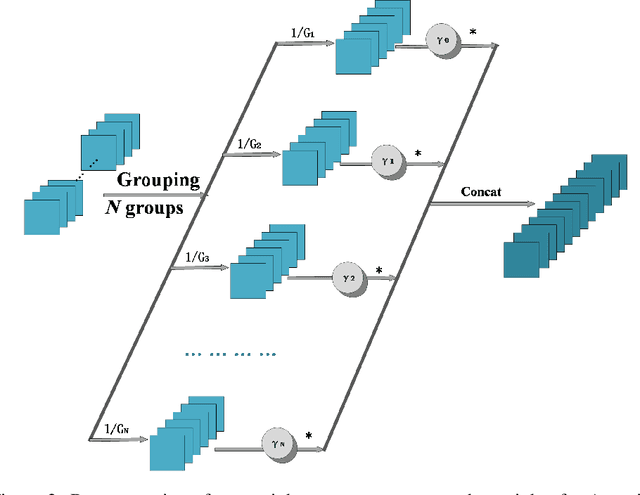

Differentiable Architecture Search (DARTS) provides a baseline for searching effective network architectures based gradient, but it is accompanied by huge computational overhead in searching and training network architecture. Recently, many novel works have improved DARTS. Particularly, Partially-Connected DARTS(PC-DARTS) proposed the partial channel sampling technique which achieved good results. In this work, we found that the backbone provided by DARTS is prone to overfitting. To mitigate this problem, we propose an approach named Group-DARTS with Attention (G-DARTS-A), using multiple groups of channels for searching. Inspired by the partially sampling strategy of PC-DARTS, we use groups channels to sample the super-network to perform a more efficient search while maintaining the relative integrity of the network information. In order to relieve the competition between channel groups and keep channel balance, we follow the attention mechanism in Squeeze-and-Excitation Network. Each group of channels shares defined weights thence they can provide different suggestion for searching. The searched architecture is more powerful and better adapted to different deployments. Specifically, by only using the attention module on DARTS we achieved an error rate of 2.82%/16.36% on CIFAR10/100 with 0.3GPU-days for search process on CIFAR10. Apply our G-DARTS-A to DARTS/PC-DARTS, an error rate of 2.57%/2.61% on CIFAR10 with 0.5/0.4 GPU-days is achieved.