 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion Subspace Clustering for Incomplete Data
Paper and Code
May 22, 2022
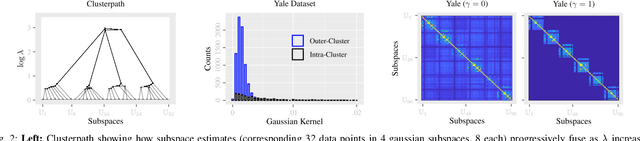

This paper introduces {\em fusion subspace clustering}, a novel method to learn low-dimensional structures that approximate large scale yet highly incomplete data. The main idea is to assign each datum to a subspace of its own, and minimize the distance between the subspaces of all data, so that subspaces of the same cluster get {\em fused} together. Our method allows low, high, and even full-rank data; it directly accounts for noise, and its sample complexity approaches the information-theoretic limit. In addition, our approach provides a natural model selection {\em clusterpath}, and a direct completion method. We give convergence guarantees, analyze computational complexity, and show through extensive experiments on real and synthetic data that our approach performs comparably to the state-of-the-art with complete data, and dramatically better if data is missing.