 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Performance Limits for Sensor-Based Robot Control and Policy Learning
Paper and Code

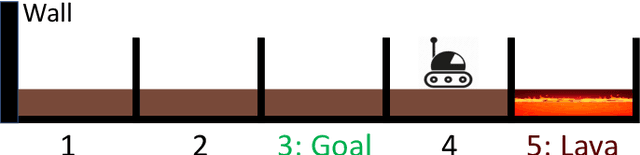
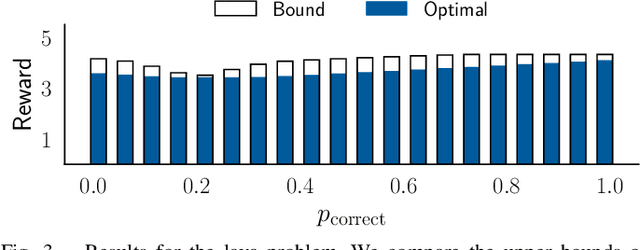
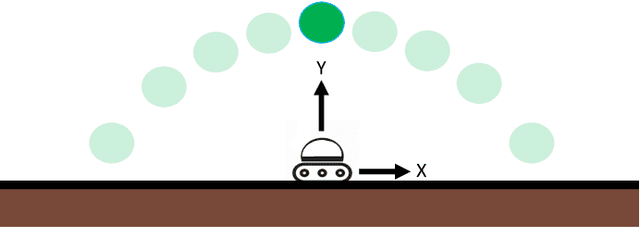
Our goal is to develop theory and algorithms for establishing fundamental limits on performance for a given task imposed by a robot's sensors. In order to achieve this, we define a quantity that captures the amount of task-relevant information provided by a sensor. Using a novel version of the generalized Fano inequality from information theory, we demonstrate that this quantity provides an upper bound on the highest achievable expected reward for one-step decision making tasks. We then extend this bound to multi-step problems via a dynamic programming approach. We present algorithms for numerically computing the resulting bounds, and demonstrate our approach on three examples: (i) the lava problem from the literature on partially observable Markov decision processes, (ii) an example with continuous state and observation spaces corresponding to a robot catching a freely-falling object, and (iii) obstacle avoidance using a depth sensor with non-Gaussian noise. We demonstrate the ability of our approach to establish strong limits on achievable performance for these problems by comparing our upper bounds with achievable lower bounds (computed by synthesizing or learning concrete control policies).