 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Few-shot Class-incremental Audio Classification Using Expandable Dual-embedding Extractor
Paper and Code
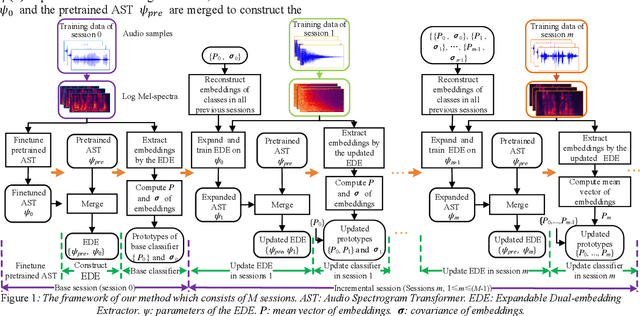

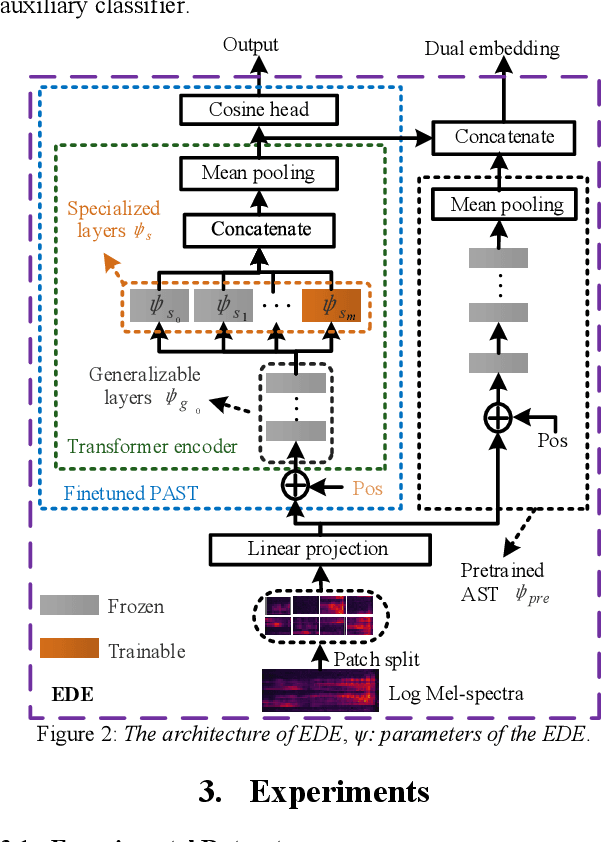
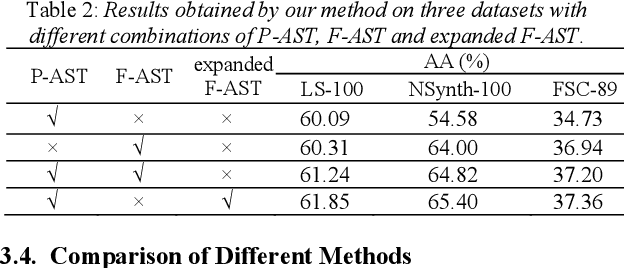
It's assumed that training data is sufficient in base session of few-shot class-incremental audio classification. However, it's difficult to collect abundant samples for model training in base session in some practical scenarios due to the data scarcity of some classes. This paper explores a new problem of fully few-shot class-incremental audio classification with few training samples in all sessions. Moreover, we propose a method using expandable dual-embedding extractor to solve it. The proposed model consists of an embedding extractor and an expandable classifier. The embedding extractor consists of a pretrained Audio Spectrogram Transformer (AST) and a finetuned AST. The expandable classifier consists of prototypes and each prototype represents a class. Experiments are conducted on three datasets (LS-100, NSynth-100 and FSC-89). Results show that our method exceeds seven baseline ones in average accuracy with statistical significance. Code is at: https://github.com/YongjieSi/EDE.