 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Kullback-Leibler-Divergence Loss for Hyperparameter-free Label Distribution Learning
Paper and Code
Sep 05, 2022
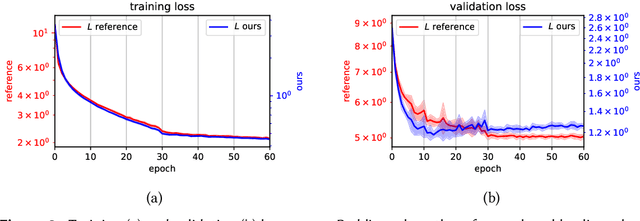

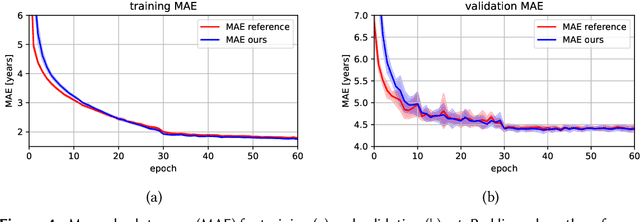
The concept of Label Distribution Learning (LDL) is a technique to stabilize classification and regression problems with ambiguous and/or imbalanced labels. A prototypical use-case of LDL is human age estimation based on profile images. Regarding this regression problem, a so called Deep Label Distribution Learning (DLDL) method has been developed. The main idea is the joint regression of the label distribution and its expectation value. However, the original DLDL method uses loss components with different mathematical motivation and, thus, different scales, which is why the use of a hyperparameter becomes necessary. In this work, we introduce a loss function for DLDL whose components are completely defined by Kullback-Leibler (KL) divergences and, thus, are directly comparable to each other without the need of additional hyperparameters. It generalizes the concept of DLDL with regard to further use-cases, in particular for multi-dimensional or multi-scale distribution learning tasks.