Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Majorization to Interpolation: Distributionally Robust Learning using Kernel Smoothing
Paper and Code
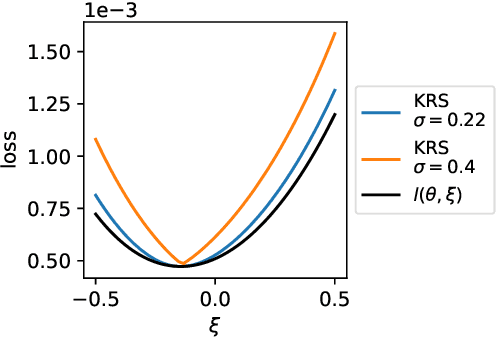
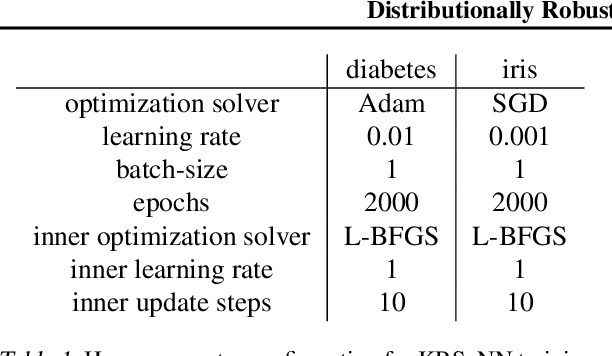
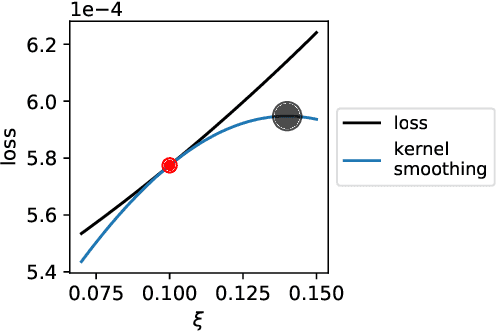
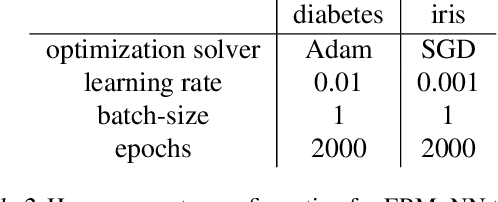
We study the function approximation aspect of distributionally robust optimization (DRO) based on probability metrics, such as the Wasserstein and the maximum mean discrepancy. Our analysis leverages the insight that existing DRO paradigms hinge on function majorants such as the Moreau-Yosida regularization (supremal convolution). Deviating from those, this paper instead proposes robust learning algorithms based on smooth function approximation and interpolation. Our methods are simple in forms and apply to general loss functions without knowing functional norms a priori. Furthermore, we analyze the DRO risk bound decomposition by leveraging smooth function approximators and the convergence rate for empirical kernel mean embedding.
View paper on