 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Game-theoretic Multi-agent Log Linear Learning to Reinforcement Learning
Paper and Code
Sep 18, 2018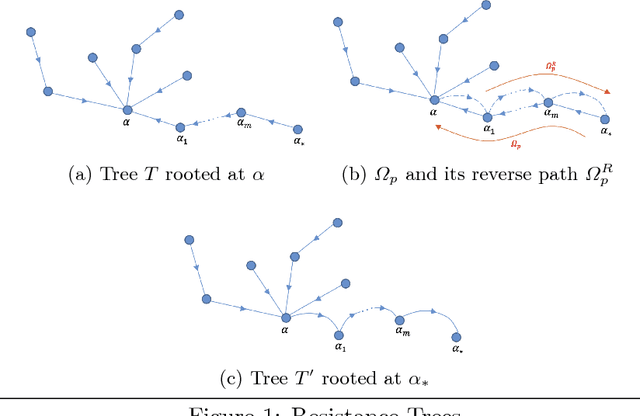
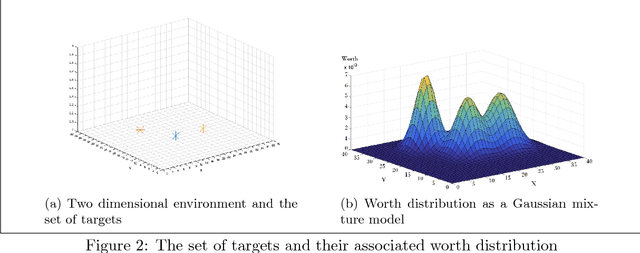
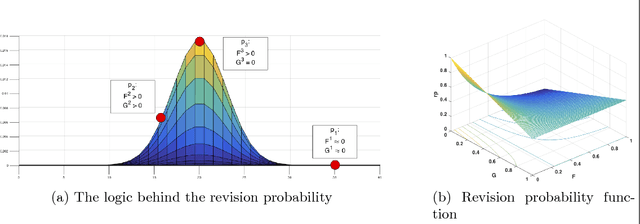

The main focus of this paper is on enhancement of two types of game-theoretic learning algorithms: log-linear learning and reinforcement learning. The standard analysis of log-linear learning needs a highly structured environment, i.e. strong assumptions about the game from an implementation perspective. In this paper, we introduce a variant of log-linear learning that provides asymptotic guarantees while relaxing the structural assumptions to include synchronous updates and limitations in information available to the players. On the other hand, model-free reinforcement learning is able to perform even under weaker assumptions on players' knowledge about the environment and other players' strategies. We propose a reinforcement algorithm that uses a double-aggregation scheme in order to deepen players' insight about the environment and constant learning step-size which achieves a higher convergence rate. Numerical experiments are conducted to verify each algorithm's robustness and performance.