 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Environmental Sound Representation to Robustness of 2D CNN Models Against Adversarial Attacks
Paper and Code
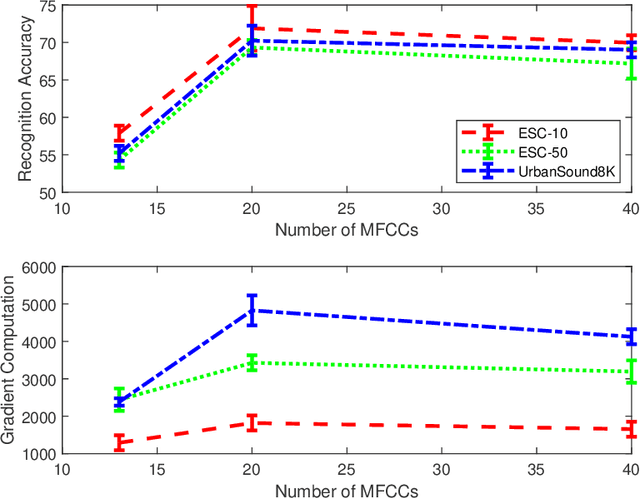
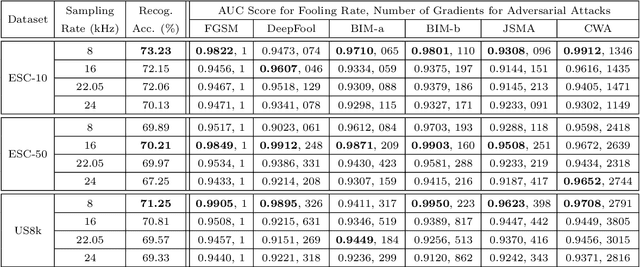
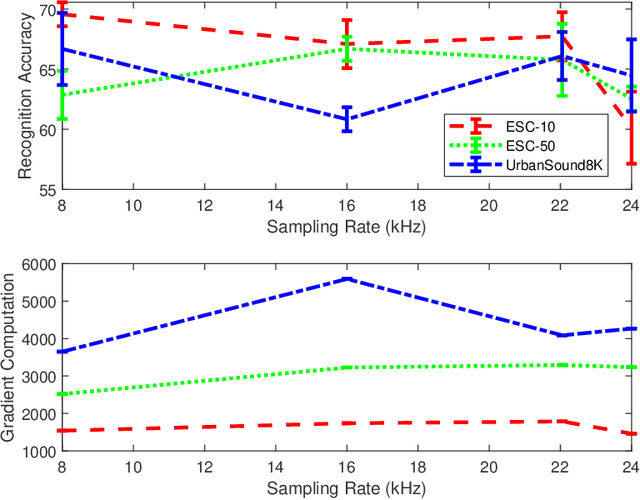
This paper investigates the impact of different standard environmental sound representations (spectrograms) on the recognition performance and adversarial attack robustness of a victim residual convolutional neural network, namely ResNet-18. Our main motivation for focusing on such a front-end classifier rather than other complex architectures is balancing recognition accuracy and the total number of training parameters. Herein, we measure the impact of different settings required for generating more informative Mel-frequency cepstral coefficient (MFCC), short-time Fourier transform (STFT), and discrete wavelet transform (DWT) representations on our front-end model. This measurement involves comparing the classification performance over the adversarial robustness. We demonstrate an inverse relationship between recognition accuracy and model robustness against six benchmarking attack algorithms on the balance of average budgets allocated by the adversary and the attack cost. Moreover, our experimental results have shown that while the ResNet-18 model trained on DWT spectrograms achieves a high recognition accuracy, attacking this model is relatively more costly for the adversary than other 2D representations. We also report some results on different convolutional neural network architectures such as ResNet-34, ResNet-56, AlexNet, and GoogLeNet, SB-CNN, and LSTM-based.