 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Data to Actions in Intelligent Transportation Systems: a Prescription of Functional Requirements for Model Actionability
Paper and Code
Feb 06, 2020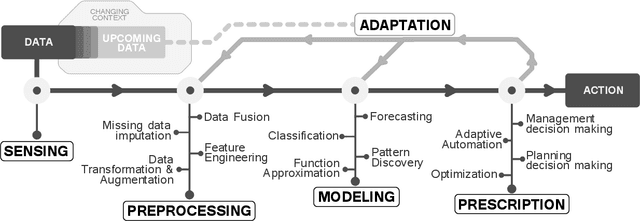
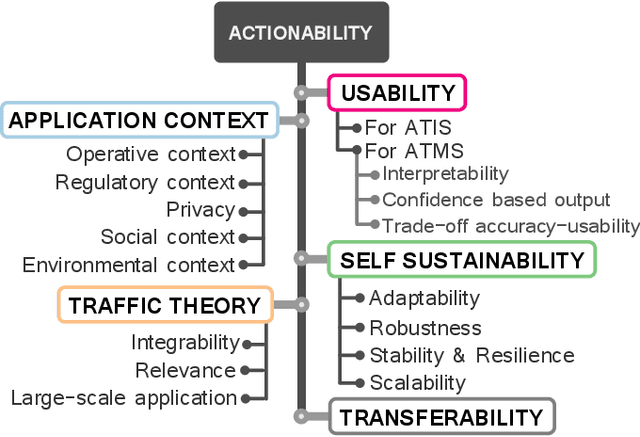
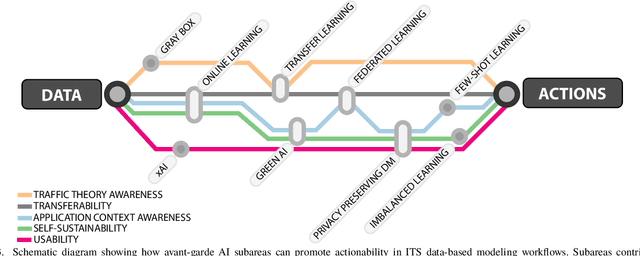
Advances in Data Science are lately permeating every field of Transportation Science and Engineering, making it straightforward to imagine that developments in the transportation sector will be data-driven. Nowadays, Intelligent Transportation Systems (ITS) could be arguably approached as a "story" intensively producing and consuming large amounts of data. A diversity of sensing devices densely spread over the infrastructure, vehicles or the travelers' personal devices act as sources of data flows that are eventually fed to software running on automatic devices, actuators or control systems producing, in turn, complex information flows between users, traffic managers, data analysts, traffic modeling scientists, etc. These information flows provide enormous opportunities to improve model development and decision-making. The present work aims to describe how data, coming from diverse ITS sources, can be used to learn and adapt data-driven models for efficiently operating ITS assets, systems and processes; in other words, for data-based models to fully become actionable. Grounded on this described data modeling pipeline for ITS, we define the characteristics, engineering requisites and challenges intrinsic to its three compounding stages, namely, data fusion, adaptive learning and model evaluation. We deliberately generalize model learning to be adaptive, since, in the core of our paper is the firm conviction that most learners will have to adapt to the everchanging phenomenon scenario underlying the majority of ITS applications. Finally, we provide a prospect of current research lines within the Data Science realm that can bring notable advances to data-based ITS modeling, which will eventually bridge the gap towards the practicality and actionability of such models.