 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeze and Chaos for DNNs: an NTK view of Batch Normalization, Checkerboard and Boundary Effects
Paper and Code
Jul 11, 2019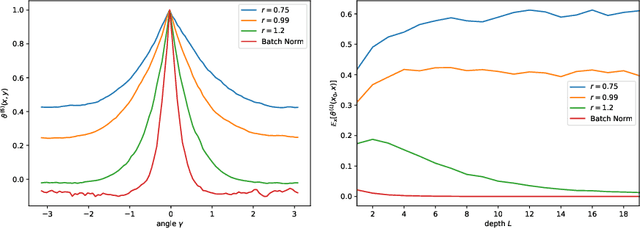


In this paper, we analyze a number of architectural features of Deep Neural Networks (DNNs), using the so-called Neural Tangent Kernel (NTK). The NTK describes the training trajectory and generalization of DNNs in the infinite-width limit. In this limit, we show that for (fully-connected) DNNs, as the depth grows, two regimes appear: "freeze" (also known as "order"), where the (scaled) NTK converges to a constant (slowing convergence), and "chaos", where it converges to a Kronecker delta (limiting generalization). We show that when using the scaled ReLU as a nonlinearity, we naturally end up in the "freeze". We show that Batch Normalization (BN) avoids the freeze regime by reducing the importance of the constant mode in the NTK. A similar effect is obtained by normalizing the nonlinearity which moves the network to the chaotic regime. We uncover the same "freeze" and "chaos" modes in Deep Deconvolutional Networks (DC-NNs). The "freeze" regime is characterized by checkerboard patterns in the image space in addition to the constant modes in input space. Finally, we introduce a new NTK-based parametrization to eliminate border artifacts and we propose a layer-dependent learning rate to improve the convergence of DC-NNs. We illustrate our findings by training DCGANs using our setup. When trained in the "freeze" regime, we see that the generator collapses to a checkerboard mode. We also demonstrate numerically that the generator collapse can be avoided and that good quality samples can be obtained, by tuning the nonlinearity to reach the "chaos" regime (without using batch normalization).