 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFREEtree: A Tree-based Approach for High Dimensional Longitudinal Data With Correlated Features
Paper and Code
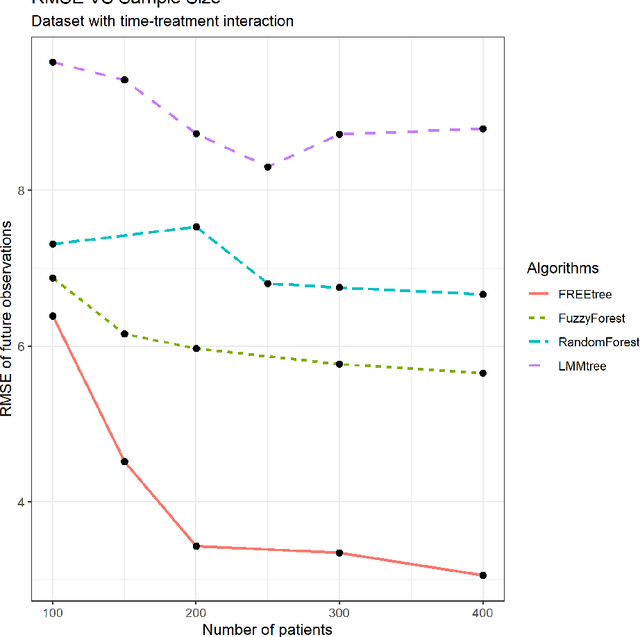

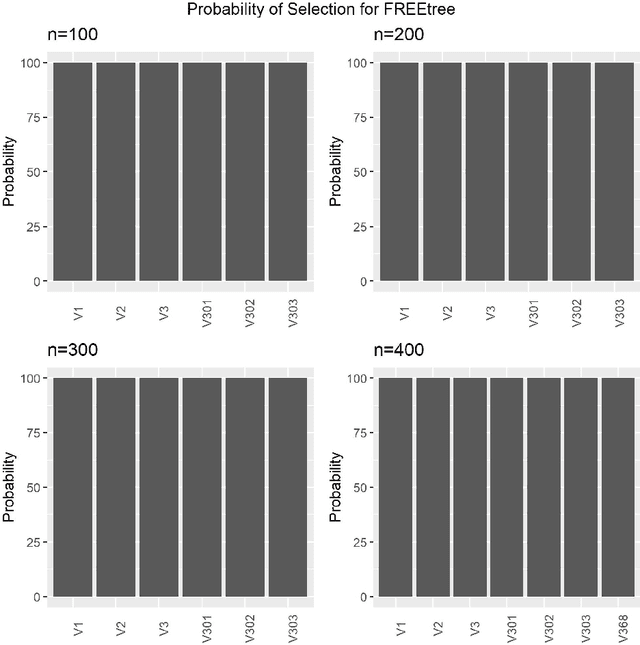

This paper proposes FREEtree, a tree-based method for high dimensional longitudinal data with correlated features. Popular machine learning approaches, like Random Forests, commonly used for variable selection do not perform well when there are correlated features and do not account for data observed over time. FREEtree deals with longitudinal data by using a piecewise random effects model. It also exploits the network structure of the features by first clustering them using weighted correlation network analysis, namely WGCNA. It then conducts a screening step within each cluster of features and a selection step among the surviving features, that provides a relatively unbiased way to select features. By using dominant principle components as regression variables at each leaf and the original features as splitting variables at splitting nodes, FREEtree maintains its interpretability and improves its computational efficiency. The simulation results show that FREEtree outperforms other tree-based methods in terms of prediction accuracy, feature selection accuracy, as well as the ability to recover the underlying structure.