 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundations of data imbalance and solutions for a data democracy
Paper and Code
Jul 30, 2021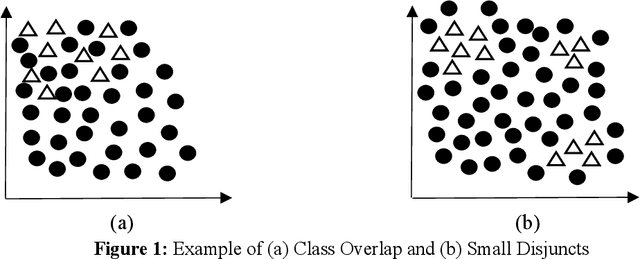

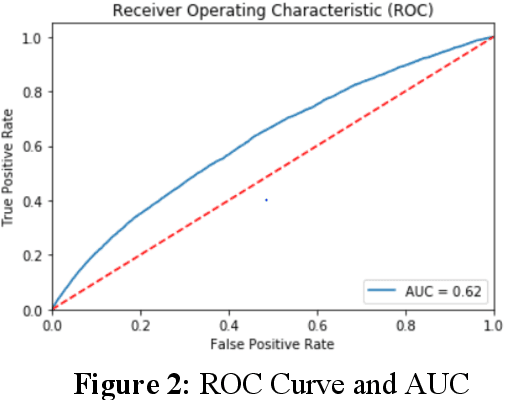

Dealing with imbalanced data is a prevalent problem while performing classification on the datasets. Many times, this problem contributes to bias while making decisions or implementing policies. Thus, it is vital to understand the factors which cause imbalance in the data (or class imbalance). Such hidden biases and imbalances can lead to data tyranny and a major challenge to a data democracy. In this chapter, two essential statistical elements are resolved: the degree of class imbalance and the complexity of the concept; solving such issues helps in building the foundations of a data democracy. Furthermore, statistical measures which are appropriate in these scenarios are discussed and implemented on a real-life dataset (car insurance claims). In the end, popular data-level methods such as random oversampling, random undersampling, synthetic minority oversampling technique, Tomek link, and others are implemented in Python, and their performance is compared.