 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFortify the Shortest Stave in Attention: Enhancing Context Awareness of Large Language Models for Effective Tool Use
Paper and Code
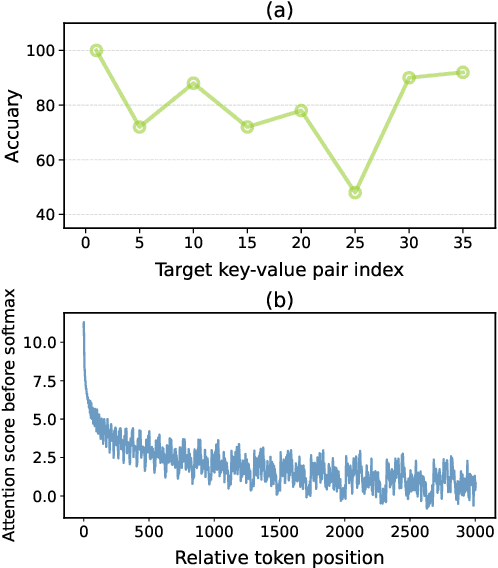
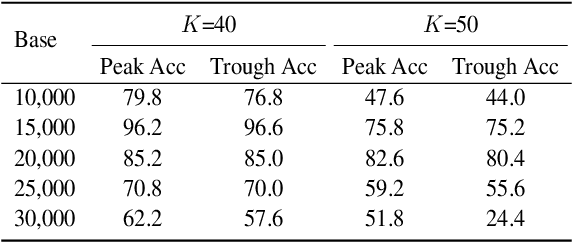

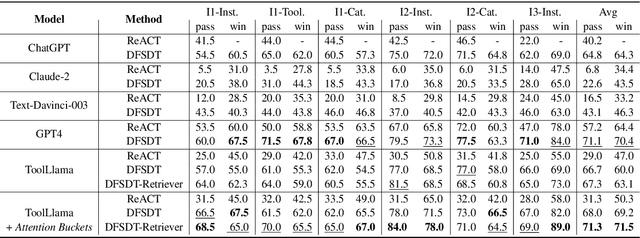
Recent advancements in large language models (LLMs) have significantly expanded their functionality and skills as tool agents. In this paper, we argue that a waveform pattern in the model's attention allocation has an impact on the tool use performance, which degrades when the position of essential information hits the trough zone. To address this issue, we propose a novel inference method named Attention Buckets. This approach enables LLMs to handle context by conducting parallel processes, each featuring a unique RoPE angle base that shapes the attention waveform. Attention Buckets ensures that an attention trough of a particular process can be compensated with an attention peak of another run, reducing the risk of the LLM missing essential information residing within the attention trough. Our extensive experiments on the widely recognized tool use benchmark demonstrate the efficacy of our approach, where a 7B-parameter open-source model enhanced by Attention Buckets achieves SOTA performance on par with GPT-4.