 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORESEE: Model-based Reinforcement Learning using Unscented Transform with application to Tuning of Control Barrier Functions
Paper and Code

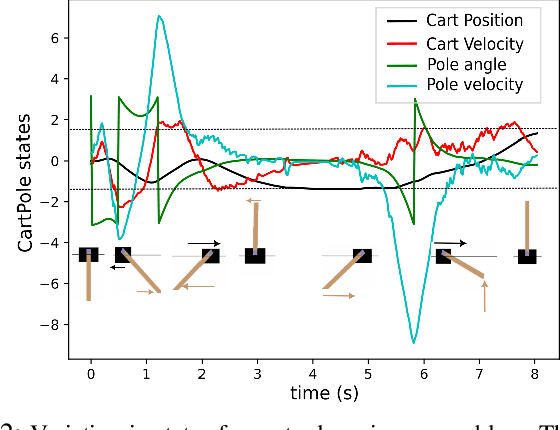


In this paper, we introduce a novel online model-based reinforcement learning algorithm that uses Unscented Transform to propagate uncertainty for the prediction of the future reward. Previous approaches either approximate the state distribution at each step of the prediction horizon with a Gaussian, or perform Monte Carlo simulations to estimate the rewards. Our method, depending on the number of sigma points employed, can propagate either mean and covariance with minimal points, or higher-order moments with more points similarly to Monte Carlo. The whole framework is implemented as a computational graph for online training. Furthermore, in order to prevent explosion in the number of sigma points when propagating through a generic state-dependent uncertainty model, we add sigma-point expansion and contraction layers to our graph, which are designed using the principle of moment matching. Finally, we propose gradient descent inspired by Sequential Quadratic Programming to update policy parameters in the presence of state constraints. We demonstrate the proposed method with two applications in simulation. The first one designs a stabilizing controller for the cart-pole problem when the dynamics is known with state-dependent uncertainty. The second example, following up on our previous work, tunes the parameters of a control barrier function-based Quadratic Programming controller for a leader-follower problem in the presence of input constraints.