 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecastQA: Machine Comprehension of Temporal Text for Answering Forecasting Questions
Paper and Code
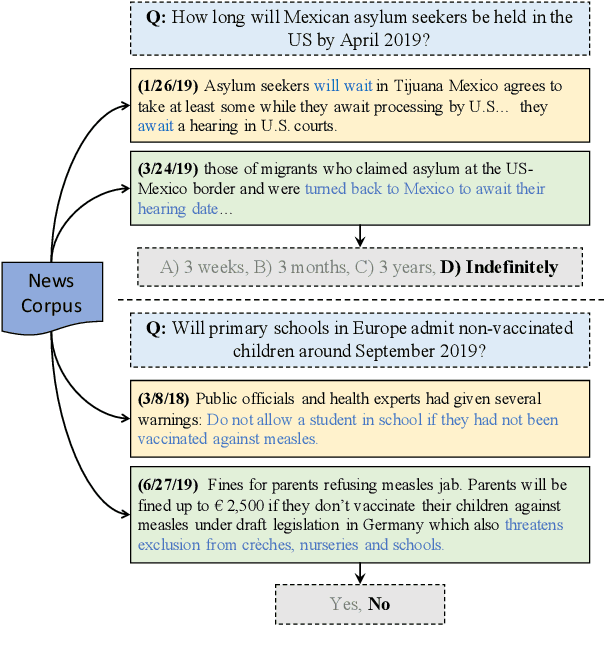
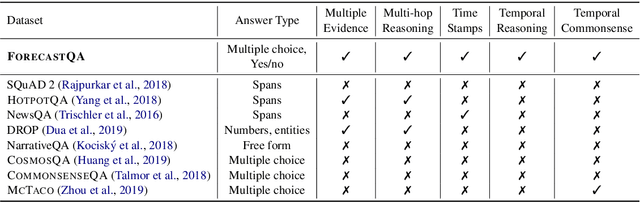

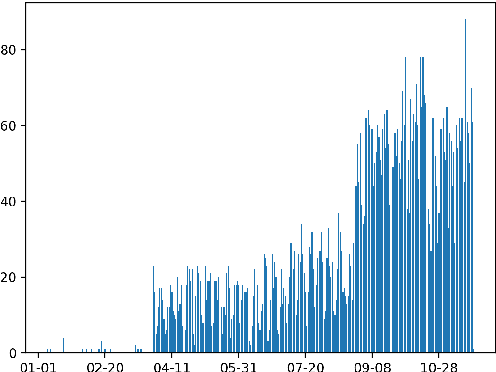
Textual data are often accompanied by time information (e.g., dates in news articles), but the information is easily overlooked on existing question answering datasets. In this paper, we introduce ForecastQA, a new open-domain question answering dataset consisting of 10k questions which requires temporal reasoning. ForecastQA is collected via a crowdsourcing effort based on news articles, where workers were asked to come up with yes-no or multiple-choice questions. We also present baseline models for our dataset, which is based on a pre-trained language model. In our study, our baseline model achieves 61.6% accuracy on the ForecastQA dataset. We expect that our new data will support future research efforts. Our data and code are publicly available at https://inklab.usc.edu/ForecastQA/.