 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlattenQuant: Breaking Through the Inference Compute-bound for Large Language Models with Per-tensor Quantization
Paper and Code
Feb 28, 2024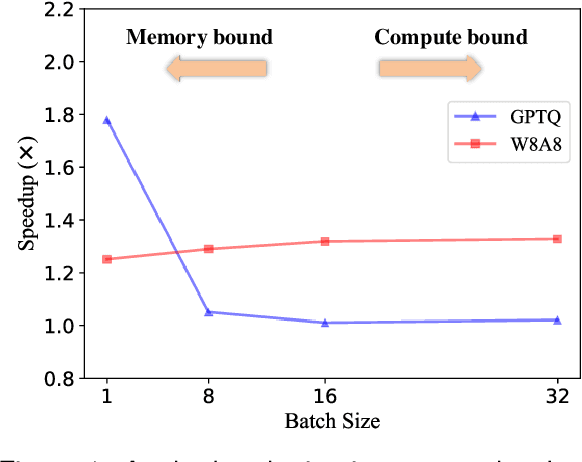

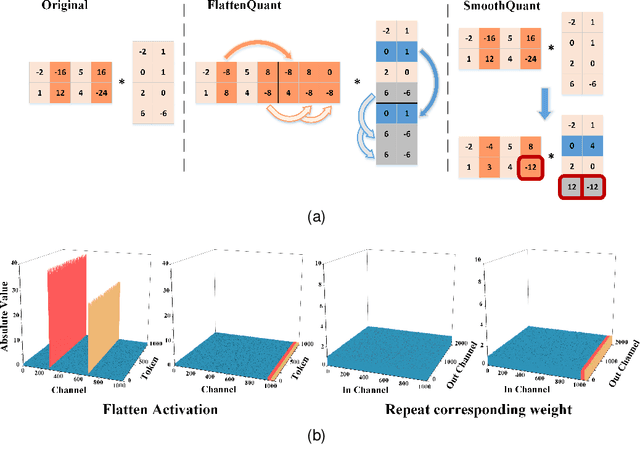
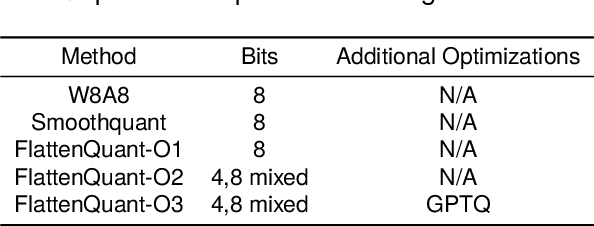
Large language models (LLMs) have demonstrated state-of-the-art performance across various tasks. However, the latency of inference and the large GPU memory consumption of LLMs restrict their deployment performance. Recently, there have been some efficient attempts to quantize LLMs, yet inference with large batch size or long sequence still has the issue of being compute-bound. Fine-grained quantization methods have showcased their proficiency in achieving low-bit quantization for LLMs, while requiring FP16 data type for linear layer computations, which is time-consuming when dealing with large batch size or long sequence. In this paper, we introduce a method called FlattenQuant, which significantly reduces the maximum value of the tensor by flattening the large channels in the tensor, to achieve low bit per-tensor quantization with minimal accuracy loss. Our experiments show that FlattenQuant can directly use 4 bits to achieve 48.29% of the linear layer calculation in LLMs, with the remaining layers using 8 bits. The 4-bit matrix multiplication introduced in the FlattenQuant method can effectively address the compute-bound caused by large matrix calculation. Our work achieves up to 2$\times$ speedup and 2.3$\times$ memory reduction for LLMs with negligible loss in accuracy.