Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-point optimization of deep neural networks with adaptive step size retraining
Paper and Code
Feb 27, 2017
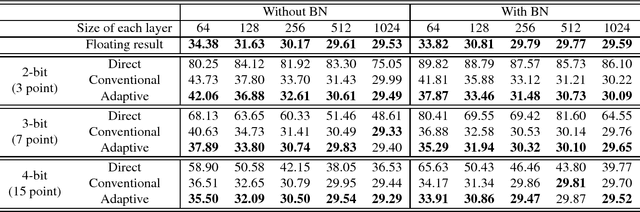
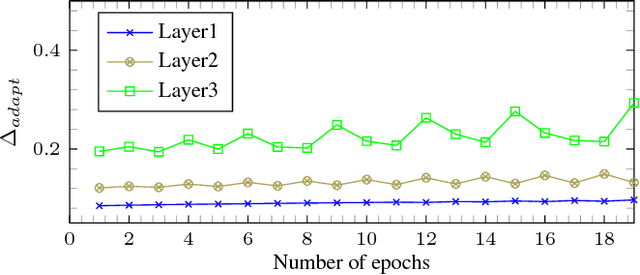

Fixed-point optimization of deep neural networks plays an important role in hardware based design and low-power implementations. Many deep neural networks show fairly good performance even with 2- or 3-bit precision when quantized weights are fine-tuned by retraining. We propose an improved fixedpoint optimization algorithm that estimates the quantization step size dynamically during the retraining. In addition, a gradual quantization scheme is also tested, which sequentially applies fixed-point optimizations from high- to low-precision. The experiments are conducted for feed-forward deep neural networks (FFDNNs), convolutional neural networks (CNNs), and recurrent neural networks (RNNs).
* This paper is accepted in ICASSP 2017
View paper on