 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-Length Protein Embeddings using Contextual Lenses
Paper and Code
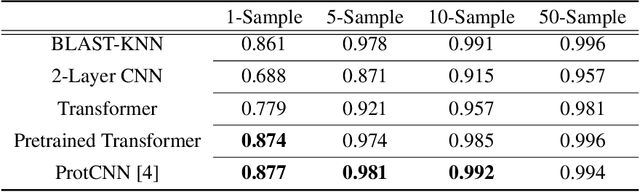
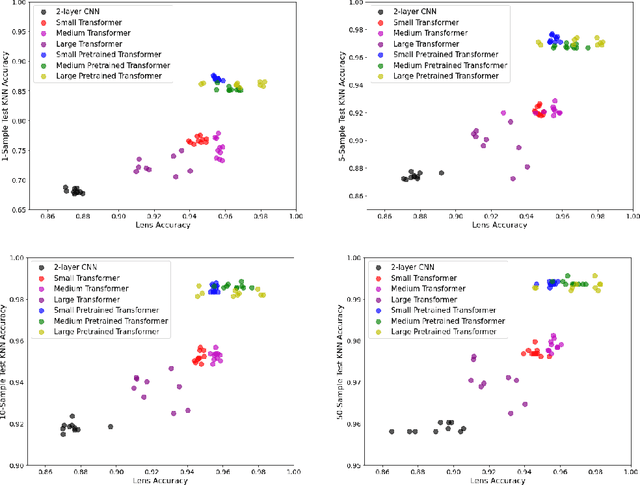
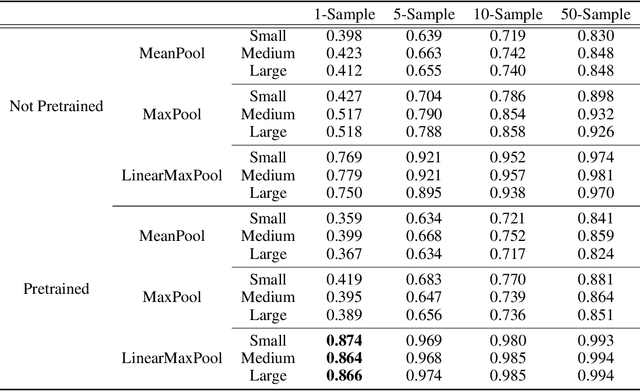
The Basic Local Alignment Search Tool (BLAST) is currently the most popular method for searching databases of biological sequences. BLAST compares sequences via similarity defined by a weighted edit distance, which results in it being computationally expensive. As opposed to working with edit distance, a vector similarity approach can be accelerated substantially using modern hardware or hashing techniques. Such an approach would require fixed-length embeddings for biological sequences. There has been recent interest in learning fixed-length protein embeddings using deep learning models under the hypothesis that the hidden layers of supervised or semi-supervised models could produce potentially useful vector embeddings. We consider transformer (BERT) protein language models that are pretrained on the TrEMBL data set and learn fixed-length embeddings on top of them with contextual lenses. The embeddings are trained to predict the family a protein belongs to for sequences in the Pfam database. We show that for nearest-neighbor family classification, pretraining offers a noticeable boost in performance and that the corresponding learned embeddings are competitive with BLAST. Furthermore, we show that the raw transformer embeddings, obtained via static pooling, do not perform well on nearest-neighbor family classification, which suggests that learning embeddings in a supervised manner via contextual lenses may be a compute-efficient alternative to fine-tuning.