 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFix-A-Step: Effective Semi-supervised Learning from Uncurated Unlabeled Sets
Paper and Code


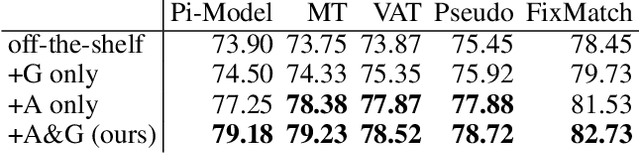
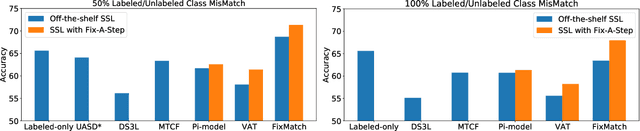
Semi-supervised learning (SSL) promises gains in accuracy compared to training classifiers on small labeled datasets by also training on many unlabeled images. In realistic applications like medical imaging, unlabeled sets will be collected for expediency and thus uncurated: possibly different from the labeled set in represented classes or class frequencies. Unfortunately, modern deep SSL often makes accuracy worse when given uncurated unlabeled sets. Recent remedies suggest filtering approaches that detect out-of-distribution unlabeled examples and then discard or downweight them. Instead, we view all unlabeled examples as potentially helpful. We introduce a procedure called Fix-A-Step that can improve heldout accuracy of common deep SSL methods despite lack of curation. The key innovations are augmentations of the labeled set inspired by all unlabeled data and a modification of gradient descent updates to prevent following the multi-task SSL loss from hurting labeled-set accuracy. Though our method is simpler than alternatives, we show consistent accuracy gains on CIFAR-10 and CIFAR-100 benchmarks across all tested levels of artificial contamination for the unlabeled sets. We further suggest a real medical benchmark for SSL: recognizing the view type of ultrasound images of the heart. Our method can learn from 353,500 truly uncurated unlabeled images to deliver gains that generalize across hospitals.