 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst-Order Manifold Data Augmentation for Regression Learning
Paper and Code
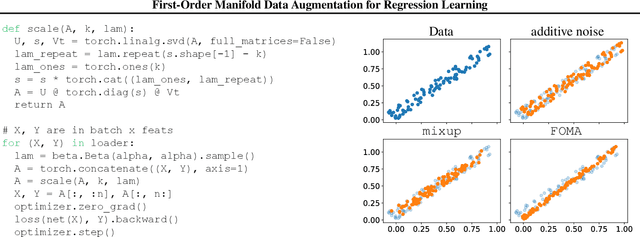
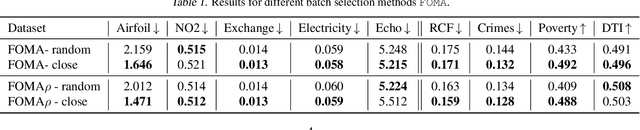
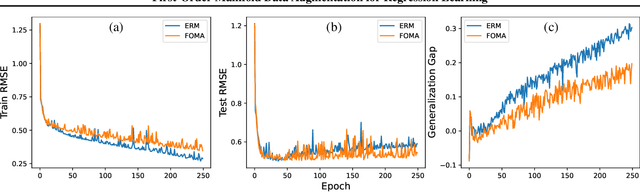

Data augmentation (DA) methods tailored to specific domains generate synthetic samples by applying transformations that are appropriate for the characteristics of the underlying data domain, such as rotations on images and time warping on time series data. In contrast, domain-independent approaches, e.g. mixup, are applicable to various data modalities, and as such they are general and versatile. While regularizing classification tasks via DA is a well-explored research topic, the effect of DA on regression problems received less attention. To bridge this gap, we study the problem of domain-independent augmentation for regression, and we introduce FOMA: a new data-driven domain-independent data augmentation method. Essentially, our approach samples new examples from the tangent planes of the train distribution. Augmenting data in this way aligns with the network tendency towards capturing the dominant features of its input signals. We evaluate FOMA on in-distribution generalization and out-of-distribution robustness benchmarks, and we show that it improves the generalization of several neural architectures. We also find that strong baselines based on mixup are less effective in comparison to our approach. Our code is publicly available athttps://github.com/azencot-group/FOMA.