Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time 4-Expert Prediction Problem
Paper and Code
Dec 03, 2019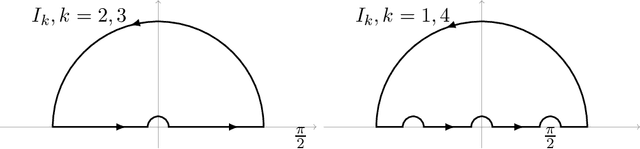
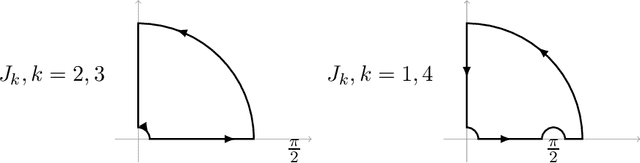
We explicitly solve the nonlinear PDE that is the continuous limit of dynamic programming of \emph{expert prediction problem} in finite horizon setting with $N=4$ experts. The \emph{expert prediction problem} is formulated as a zero sum game between a player and an adversary. By showing that the solution is $\mathcal{C}^2$, we are able to show that the strategies conjectured in arXiv:1409.3040G form an asymptotic Nash equilibrium. We also prove the "Finite vs Geometric regret" conjecture proposed in arXiv:1409.3040G for $N=4$, and and show that this conjecture in fact follows from the conjecture that the comb strategies are optimal.
* Keywords: machine learning, expert advice framework, asymptotic
expansion, inverse Laplace transform, regret minimization, Jacobi-theta
function
View paper on