 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerprint Policy Optimisation for Robust Reinforcement Learning
Paper and Code
Sep 15, 2018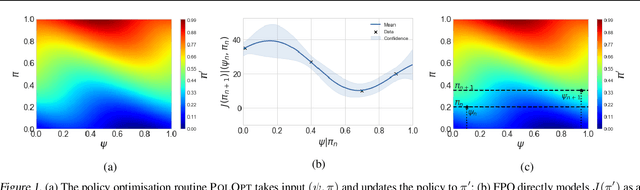
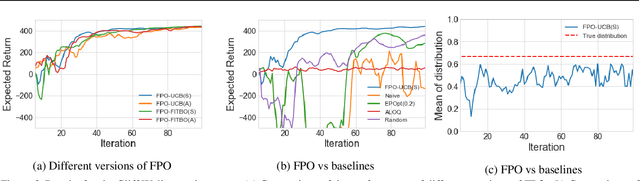
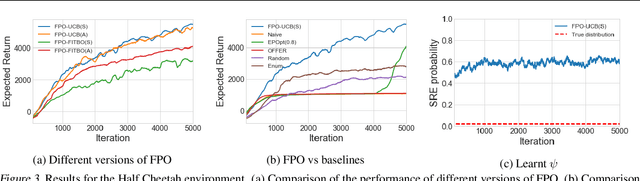
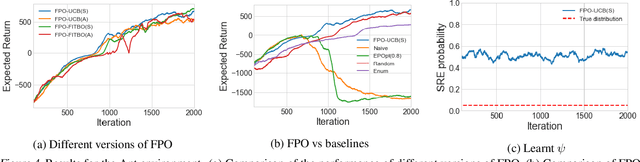
Policy gradient methods have been successfully applied to a variety of reinforcement learning tasks. However, while learning in a simulator, these methods do not utilise the opportunity to improve learning by adjusting certain environment variables: unobservable state features that are randomly determined by the environment in a physical setting, but that are controllable in a simulator. This can lead to slow learning or convergence to highly suboptimal policies if the environment variable has a large impact on the transition dynamics. In this paper, we present fingerprint policy optimisation (FPO) which finds a policy that is optimal in expectation across the distribution of environment variables. The central idea is to use Bayesian optimisation (BO) to actively select the distribution of the environment variable that maximises the improvement generated by each iteration of the policy gradient method. To make this BO practical, we contribute two easy-to-compute low-dimensional fingerprints of the current policy. We apply FPO to a number of continuous control tasks of varying difficulty and show that FPO can efficiently learn policies that are robust to significant rare events, which are unlikely to be observable under random sampling but are key to learning good policies.