 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Pretrained Vision-Language Models with Correlation Information Bottleneck for Robust Visual Question Answering
Paper and Code
Sep 14, 2022
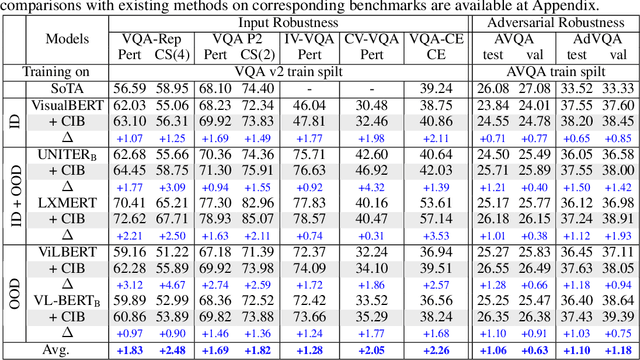


Benefiting from large-scale Pretrained Vision-Language Models (VL-PMs), the performance of Visual Question Answering (VQA) has started to approach human oracle performance. However, finetuning large-scale VL-PMs with limited data for VQA usually faces overfitting and poor generalization issues, leading to a lack of robustness. In this paper, we aim to improve the robustness of VQA systems (ie, the ability of the systems to defend against input variations and human-adversarial attacks) from the perspective of Information Bottleneck when finetuning VL-PMs for VQA. Generally, internal representations obtained by VL-PMs inevitably contain irrelevant and redundant information for the downstream VQA task, resulting in statistically spurious correlations and insensitivity to input variations. To encourage representations to converge to a minimal sufficient statistic in vision-language learning, we propose the Correlation Information Bottleneck (CIB) principle, which seeks a tradeoff between representation compression and redundancy by minimizing the mutual information (MI) between the inputs and internal representations while maximizing the MI between the outputs and the representations. Meanwhile, CIB measures the internal correlations among visual and linguistic inputs and representations by a symmetrized joint MI estimation. Extensive experiments on five VQA benchmarks of input robustness and two VQA benchmarks of human-adversarial robustness demonstrate the effectiveness and superiority of the proposed CIB in improving the robustness of VQA systems.