 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine Detailed Texture Learning for 3D Meshes with Generative Models
Paper and Code

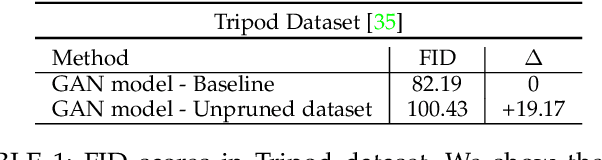


This paper presents a method to reconstruct high-quality textured 3D models from both multi-view and single-view images. The reconstruction is posed as an adaptation problem and is done progressively where in the first stage, we focus on learning accurate geometry, whereas in the second stage, we focus on learning the texture with a generative adversarial network. In the generative learning pipeline, we propose two improvements. First, since the learned textures should be spatially aligned, we propose an attention mechanism that relies on the learnable positions of pixels. Secondly, since discriminator receives aligned texture maps, we augment its input with a learnable embedding which improves the feedback to the generator. We achieve significant improvements on multi-view sequences from Tripod dataset as well as on single-view image datasets, Pascal 3D+ and CUB. We demonstrate that our method achieves superior 3D textured models compared to the previous works. Please visit our web-page for 3D visuals.