 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial misstatement detection: a realistic evaluation
Paper and Code



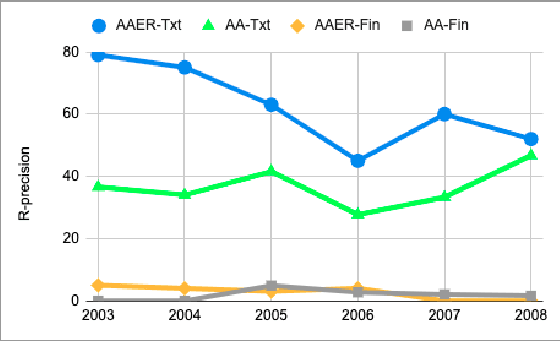
In this work, we examine the evaluation process for the task of detecting financial reports with a high risk of containing a misstatement. This task is often referred to, in the literature, as ``misstatement detection in financial reports''. We provide an extensive review of the related literature. We propose a new, realistic evaluation framework for the task which, unlike a large part of the previous work: (a) focuses on the misstatement class and its rarity, (b) considers the dimension of time when splitting data into training and test and (c) considers the fact that misstatements can take a long time to detect. Most importantly, we show that the evaluation process significantly affects system performance, and we analyze the performance of different models and feature types in the new realistic framework.