 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMFS: Federated Multimodal Fusion Learning with Selective Modality Communication
Paper and Code
Oct 10, 2023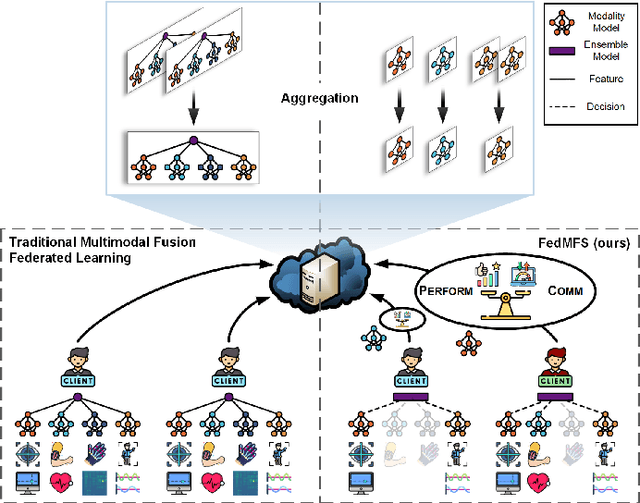
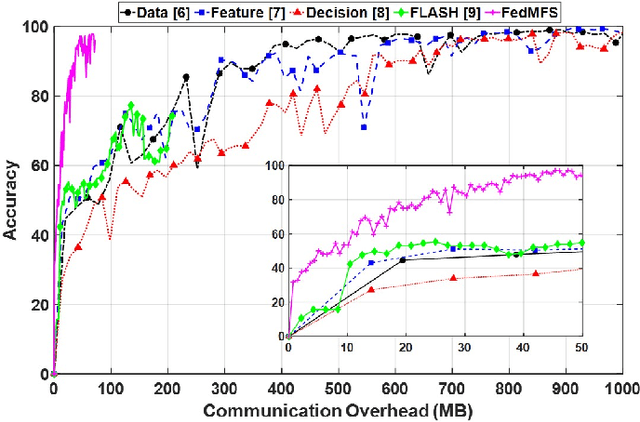

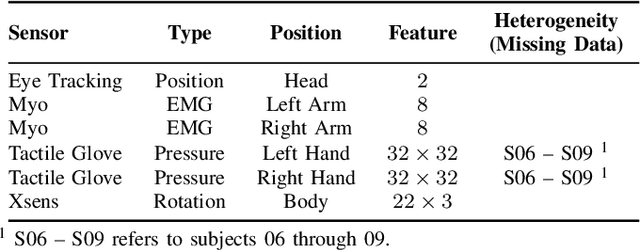
Federated learning (FL) is a distributed machine learning (ML) paradigm that enables clients to collaborate without accessing, infringing upon, or leaking original user data by sharing only model parameters. In the Internet of Things (IoT), edge devices are increasingly leveraging multimodal data compositions and fusion paradigms to enhance model performance. However, in FL applications, two main challenges remain open: (i) addressing the issues caused by heterogeneous clients lacking specific modalities and (ii) devising an optimal modality upload strategy to minimize communication overhead while maximizing learning performance. In this paper, we propose Federated Multimodal Fusion learning with Selective modality communication (FedMFS), a new multimodal fusion FL methodology that can tackle the above mentioned challenges. The key idea is to utilize Shapley values to quantify each modality's contribution and modality model size to gauge communication overhead, so that each client can selectively upload the modality models to the server for aggregation. This enables FedMFS to flexibly balance performance against communication costs, depending on resource constraints and applications. Experiments on real-world multimodal datasets demonstrate the effectiveness of FedMFS, achieving comparable accuracy while reducing communication overhead by one twentieth compared to baselines.