 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMatch: Federated Learning Over Heterogeneous Question Answering Data
Paper and Code
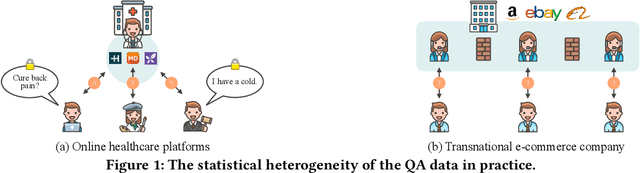
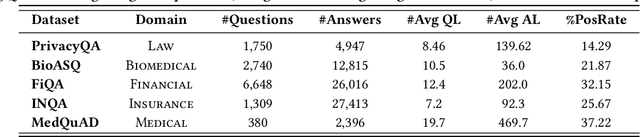
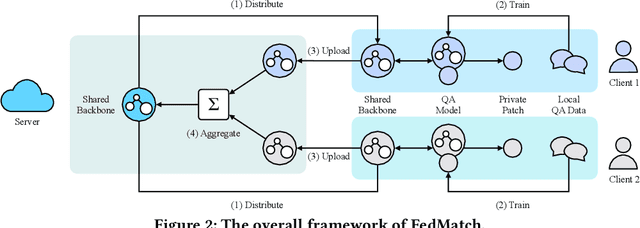
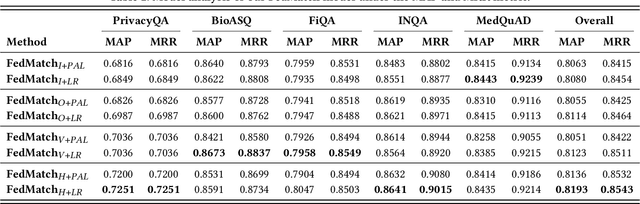
Question Answering (QA), a popular and promising technique for intelligent information access, faces a dilemma about data as most other AI techniques. On one hand, modern QA methods rely on deep learning models which are typically data-hungry. Therefore, it is expected to collect and fuse all the available QA datasets together in a common site for developing a powerful QA model. On the other hand, real-world QA datasets are typically distributed in the form of isolated islands belonging to different parties. Due to the increasing awareness of privacy security, it is almost impossible to integrate the data scattered around, or the cost is prohibited. A possible solution to this dilemma is a new approach known as federated learning, which is a privacy-preserving machine learning technique over distributed datasets. In this work, we propose to adopt federated learning for QA with the special concern on the statistical heterogeneity of the QA data. Here the heterogeneity refers to the fact that annotated QA data are typically with non-identical and independent distribution (non-IID) and unbalanced sizes in practice. Traditional federated learning methods may sacrifice the accuracy of individual models under the heterogeneous situation. To tackle this problem, we propose a novel Federated Matching framework for QA, named FedMatch, with a backbone-patch architecture. The shared backbone is to distill the common knowledge of all the participants while the private patch is a compact and efficient module to retain the domain information for each participant. To facilitate the evaluation, we build a benchmark collection based on several QA datasets from different domains to simulate the heterogeneous situation in practice. Empirical studies demonstrate that our model can achieve significant improvements against the baselines over all the datasets.