 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated LLMs Fine-tuned with Adaptive Importance-Aware LoRA
Paper and Code
Nov 10, 2024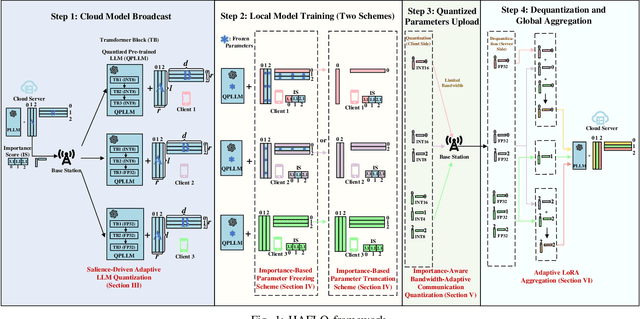
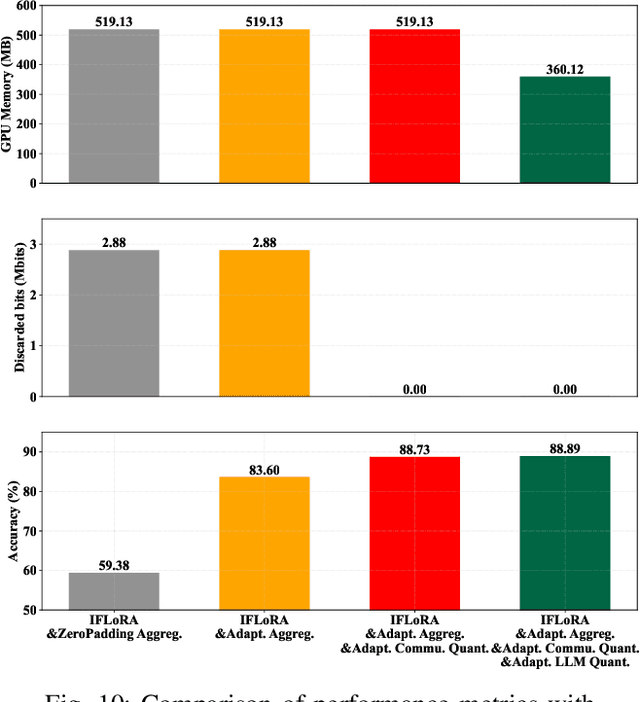
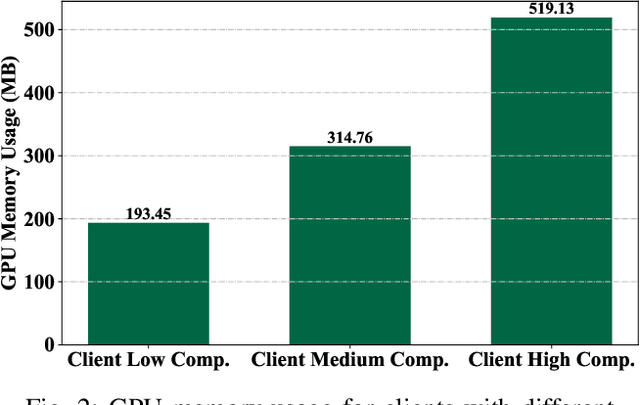
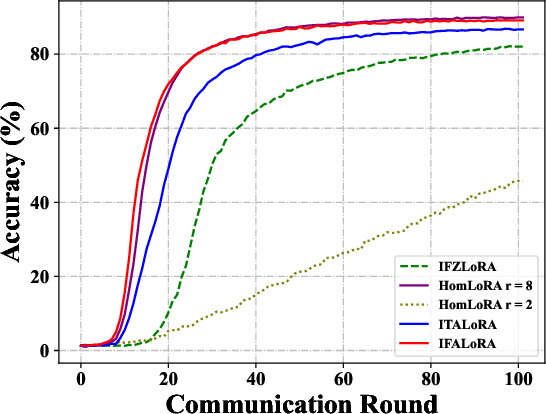
Federated fine-tuning of pre-trained Large Language Models (LLMs) enables task-specific adaptation across diverse datasets while preserving data privacy. However, the large model size and heterogeneity in client resources pose significant computational and communication challenges. To address these issues, in this paper, we propose a novel Heterogeneous Adaptive Federated Low-Rank Adaptation (LoRA) fine-tuned LLM framework (HAFL). To accommodate client resource heterogeneity, we first introduce an importance-based parameter truncation scheme, which allows clients to have different LoRA ranks, and smoothed sensitivity scores are used as importance indicators. Despite its flexibility, the truncation process may cause performance degradation. To tackle this problem, we develop an importance-based parameter freezing scheme. In this approach, both the cloud server and clients maintain the same LoRA rank, while clients selectively update only the most important decomposed LoRA rank-1 matrices, keeping the rest frozen. To mitigate the information dilution caused by the zero-padding aggregation method, we propose an adaptive aggregation approach that operates at the decomposed rank-1 matrix level. Experiments on the 20 News Group classification task show that our method converges quickly with low communication size, and avoids performance degradation when distributing models to clients compared to truncation-based heterogeneous LoRA rank scheme. Additionally, our adaptive aggregation method achieves faster convergence compared to the zero-padding approach.