 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Linear SVM with Provable Guarantees
Paper and Code
Feb 06, 2015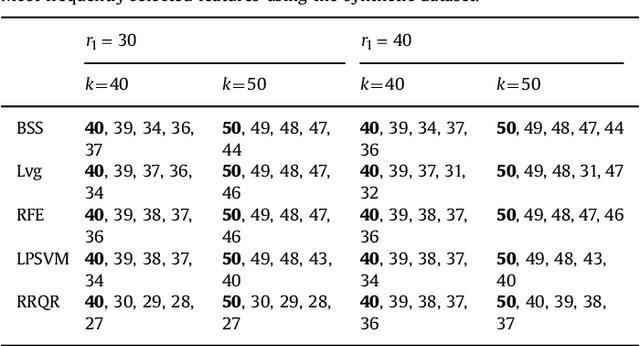
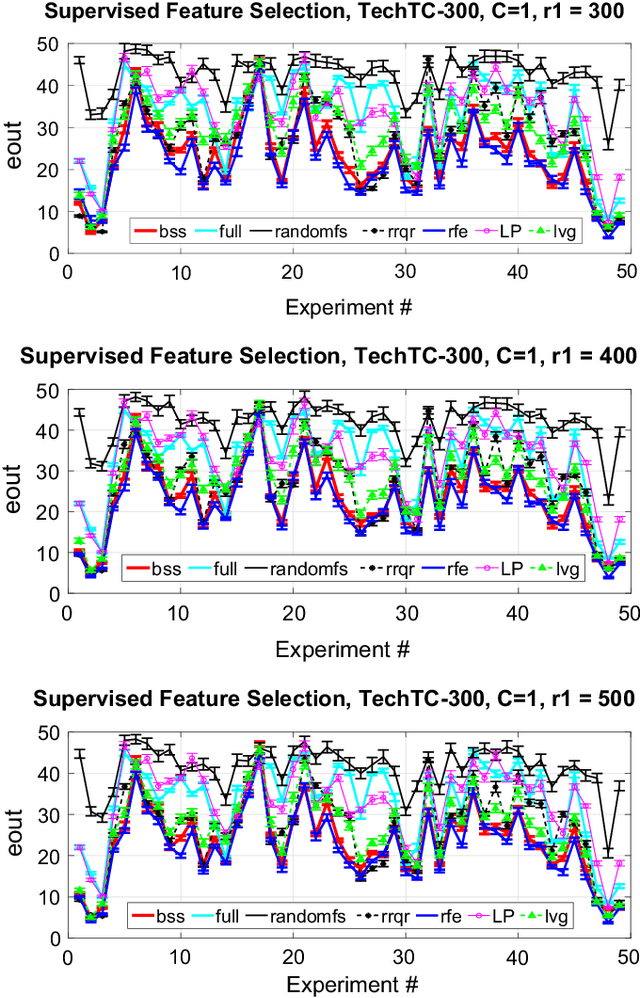
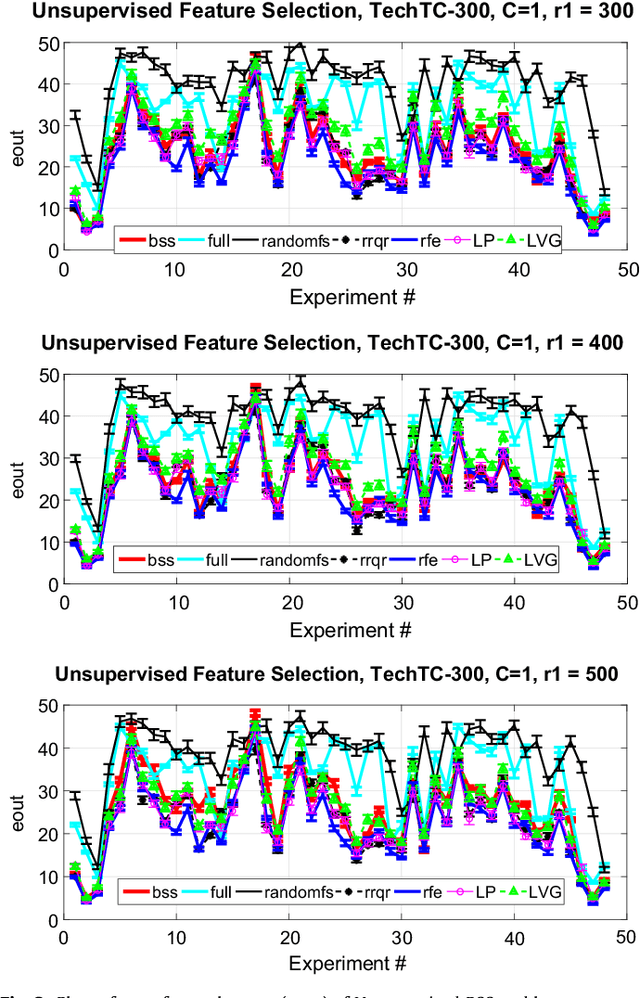
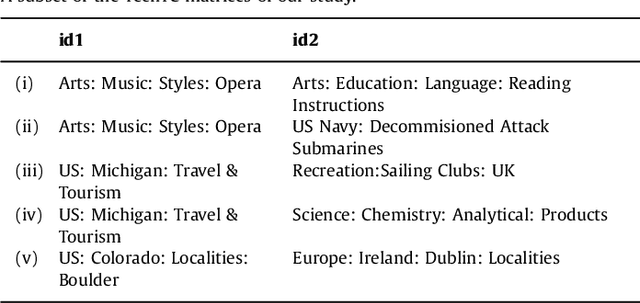
We give two provably accurate feature-selection techniques for the linear SVM. The algorithms run in deterministic and randomized time respectively. Our algorithms can be used in an unsupervised or supervised setting. The supervised approach is based on sampling features from support vectors. We prove that the margin in the feature space is preserved to within $\epsilon$-relative error of the margin in the full feature space in the worst-case. In the unsupervised setting, we also provide worst-case guarantees of the radius of the minimum enclosing ball, thereby ensuring comparable generalization as in the full feature space and resolving an open problem posed in Dasgupta et al. We present extensive experiments on real-world datasets to support our theory and to demonstrate that our method is competitive and often better than prior state-of-the-art, for which there are no known provable guarantees.