 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Huge Data via Minipatch Learning
Paper and Code
Oct 16, 2020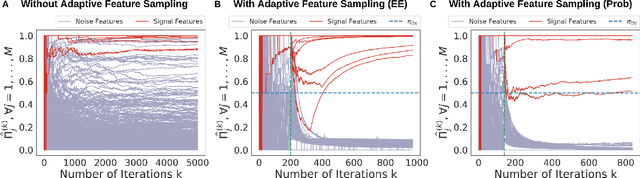
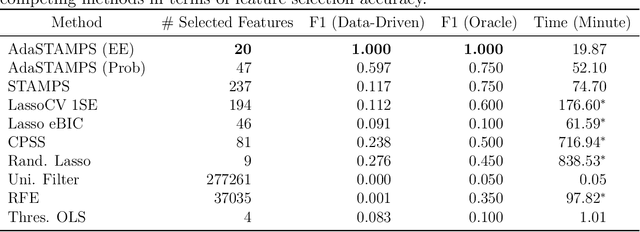
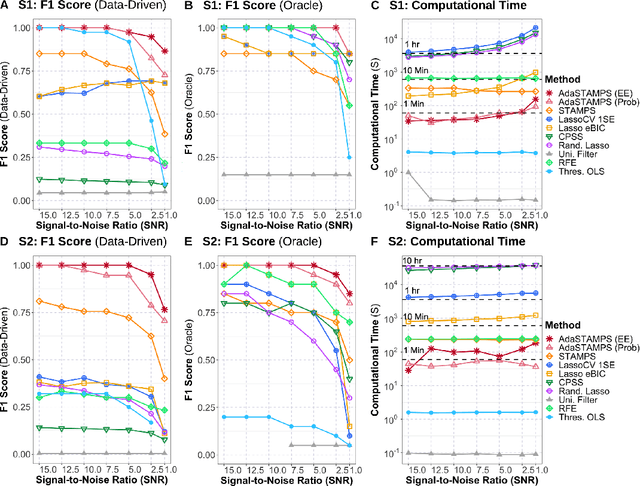
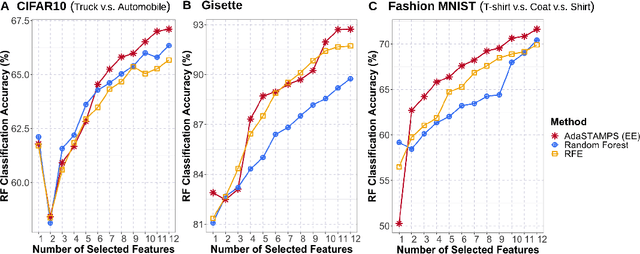
Feature selection often leads to increased model interpretability, faster computation, and improved model performance by discarding irrelevant or redundant features. While feature selection is a well-studied problem with many widely-used techniques, there are typically two key challenges: i) many existing approaches become computationally intractable in huge-data settings with millions of observations and features; and ii) the statistical accuracy of selected features degrades in high-noise, high-correlation settings, thus hindering reliable model interpretation. We tackle these problems by proposing Stable Minipatch Selection (STAMPS) and Adaptive STAMPS (AdaSTAMPS). These are meta-algorithms that build ensembles of selection events of base feature selectors trained on many tiny, (adaptively-chosen) random subsets of both the observations and features of the data, which we call minipatches. Our approaches are general and can be employed with a variety of existing feature selection strategies and machine learning techniques. In addition, we provide theoretical insights on STAMPS and empirically demonstrate that our approaches, especially AdaSTAMPS, dominate competing methods in terms of feature selection accuracy and computational time.