 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Gradients: Scalable Feature Selection via Discrete Relaxation
Paper and Code
Aug 27, 2019
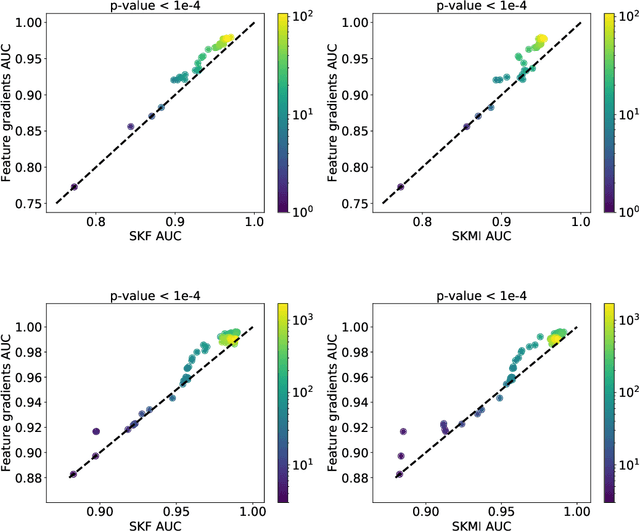

In this paper we introduce Feature Gradients, a gradient-based search algorithm for feature selection. Our approach extends a recent result on the estimation of learnability in the sublinear data regime by showing that the calculation can be performed iteratively (i.e., in mini-batches) and in linear time and space with respect to both the number of features D and the sample size N . This, along with a discrete-to-continuous relaxation of the search domain, allows for an efficient, gradient-based search algorithm among feature subsets for very large datasets. Crucially, our algorithm is capable of finding higher-order correlations between features and targets for both the N > D and N < D regimes, as opposed to approaches that do not consider such interactions and/or only consider one regime. We provide experimental demonstration of the algorithm in small and large sample-and feature-size settings.