Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility of Post-Editing Speech Transcriptions with a Mismatched Crowd
Paper and Code
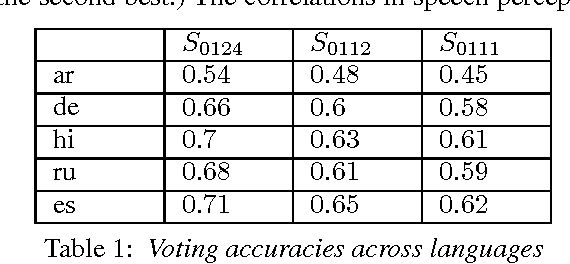
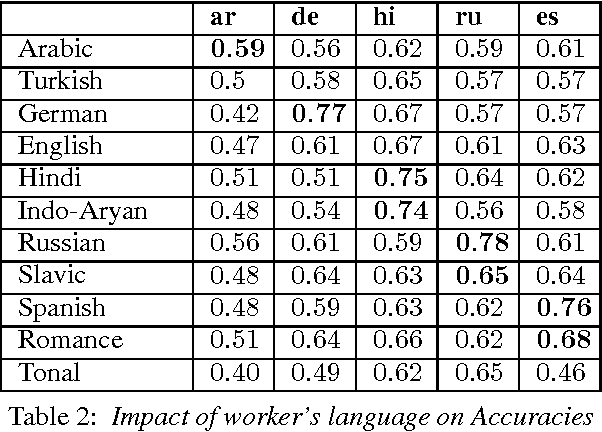
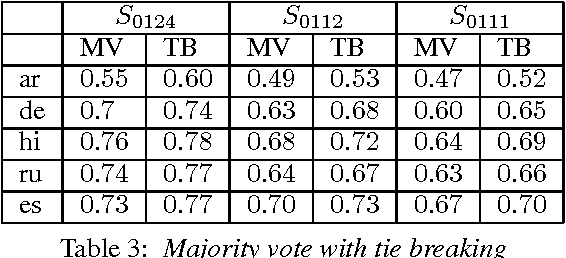
Manual correction of speech transcription can involve a selection from plausible transcriptions. Recent work has shown the feasibility of employing a mismatched crowd for speech transcription. However, it is yet to be established whether a mismatched worker has sufficiently fine-granular speech perception to choose among the phonetically proximate options that are likely to be generated from the trellis of an ASRU. Hence, we consider five languages, Arabic, German, Hindi, Russian and Spanish. For each we generate synthetic, phonetically proximate, options which emulate post-editing scenarios of varying difficulty. We consistently observe non-trivial crowd ability to choose among fine-granular options.
* HCOMP 2016 Works-in-Progress
View paper on