 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility Assessment of Multitasking in MRI Neuroimaging Analysis: Tissue Segmentation, Cross-Modality Conversion and Bias correction
Paper and Code
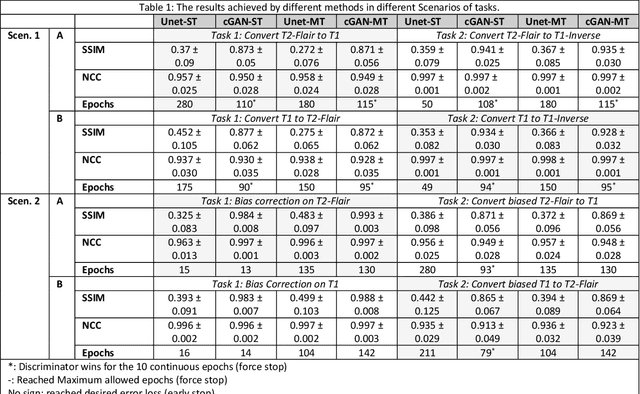
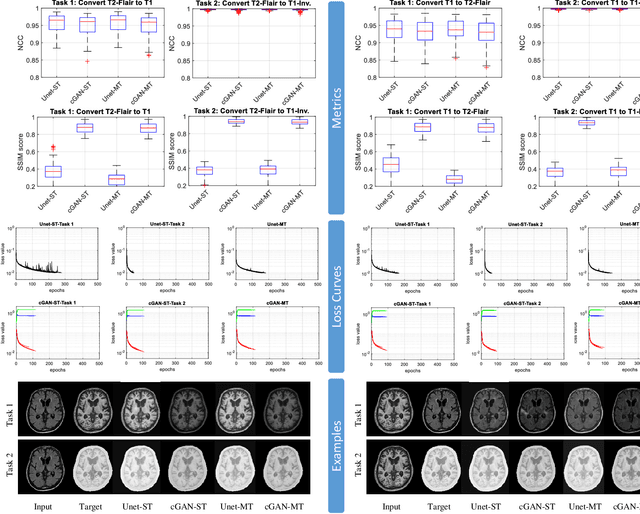
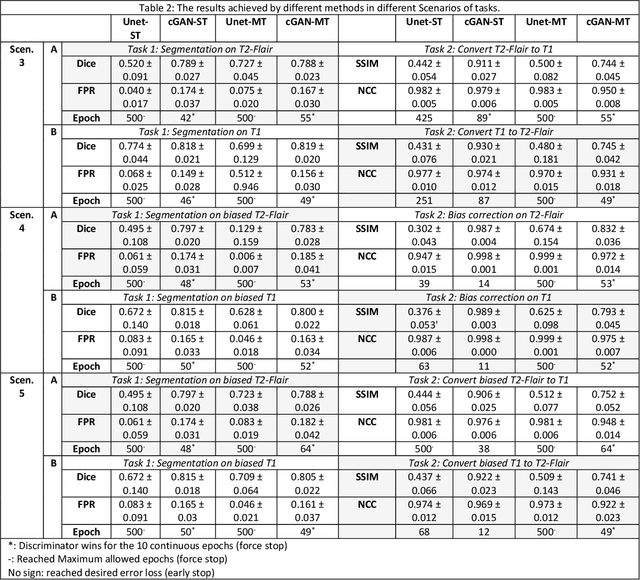
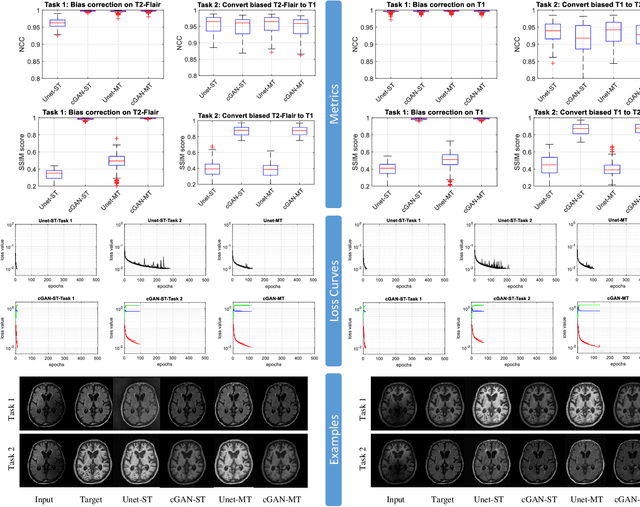
Neuroimaging is essential in brain studies for the diagnosis and identification of disease, structure, and function of the brain in its healthy and disease states. Literature shows that there are advantages of multitasking with some deep learning (DL) schemes in challenging neuroimaging applications. This study examines the feasibility of using multitasking in three different applications, including tissue segmentation, cross-modality conversion, and bias-field correction. These applications reflect five different scenarios in which multitasking is explored and 280 training and testing sessions conducted for empirical evaluations. Two well-known networks, U-Net as a well-known convolutional neural network architecture, and a closed architecture based on the conditional generative adversarial network are implemented. Different metrics such as the normalized cross-correlation coefficient and Dice scores are used for comparison of methods and results of the different experiments. Statistical analysis is also provided by paired t-test. The present study explores the pros and cons of these methods and their practical impacts on multitasking in different implementation scenarios. This investigation shows that bias correction and cross-modality conversion applications are significantly easier than the segmentation application, and having multitasking with segmentation is not reasonable if one of them is identified as the main target application. However, when the main application is the segmentation of tissues, multitasking with cross-modality conversion is beneficial, especially for the U-net architecture.