 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAVAE: Sequence Disentanglement using Information Bottleneck Principle
Paper and Code
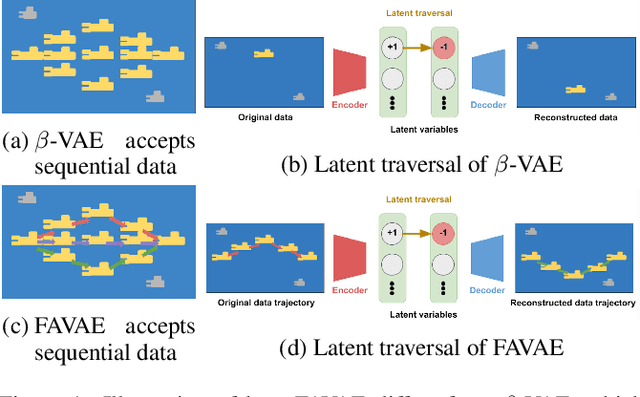
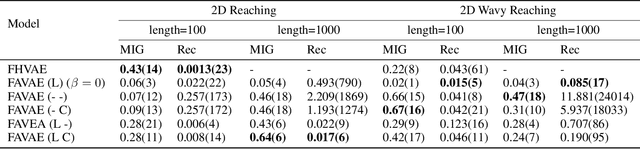
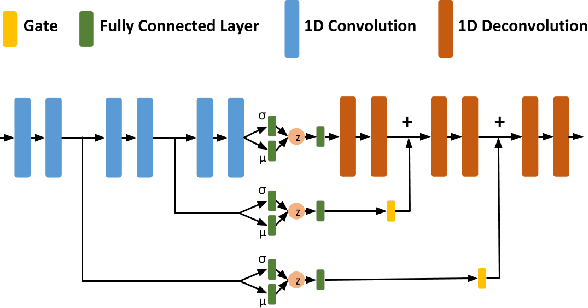
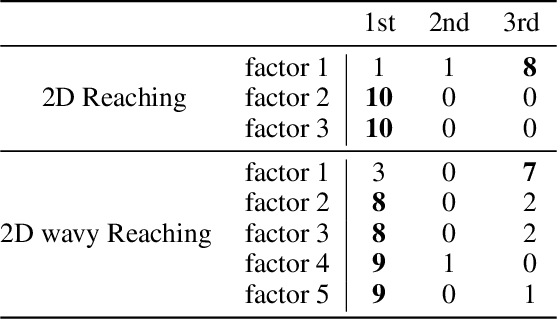
We propose the factorized action variational autoencoder (FAVAE), a state-of-the-art generative model for learning disentangled and interpretable representations from sequential data via the information bottleneck without supervision. The purpose of disentangled representation learning is to obtain interpretable and transferable representations from data. We focused on the disentangled representation of sequential data since there is a wide range of potential applications if disentanglement representation is extended to sequential data such as video, speech, and stock market. Sequential data are characterized by dynamic and static factors: dynamic factors are time dependent, and static factors are independent of time. Previous models disentangle static and dynamic factors by explicitly modeling the priors of latent variables to distinguish between these factors. However, these models cannot disentangle representations between dynamic factors, such as disentangling "picking up" and "throwing" in robotic tasks. FAVAE can disentangle multiple dynamic factors. Since it does not require modeling priors, it can disentangle "between" dynamic factors. We conducted experiments to show that FAVAE can extract disentangled dynamic factors.